
スクレイピングやAPIにて取得したデータをどういう風に保存しておくべきか?
そのデータ自体を万人が扱う場合には、csvなどでまとめておいた方が使い勝手はいいかもですよね(*’ω’*)
ただ、定期的にデータを追加していくとなるといずれ膨大な量になり、ファイルサイズになり、扱うにもファイルが重たくて大変なんてことは目に見えてるわけで。
そういえば、昔。
まだ、データベースなんてものを知らなかった時代に、テキストファイルベースでデータを管理して検索・集計して結果を表示するプログラムを作ったことがありまして。
当時のPCスペックも厳しかったし、一度調べるのに余裕で一服できちゃう(当時はタバコを吸ってたなぁ…)ぐらいの代物を使ってました。
もちろん、お仕事用に使ってたわけですが、まあ、ひどかった(;´・ω・)
それを一念発起して、データベース化した時の検索速度の向上、集計のしやすさ、ソートの手軽さたるや、感動したもんです。
さて。
今回はPythonでのデータベースということで、ここでは毎度ながら
Colaboratoryでやってみたいと思います(*’ω’*)
まずはドライブをマウント
ドライブのマウントをしてしまいましょう。
いちいち外部にデータベースファイルを置いて持ち運ぶのは面倒ですからね。
マウントの方法については


こちらを参考にしてくださいね。
sqlite3をインポート
もしかしたら必要ないかも(そもそも組み込まれてる可能性も)ですが、sqlite3をインポートします。
![]()
別段難しいところはないですね(*’ω’*)
ドライブのパスを設定してデータベースを作成
今回はドライブ上のColaboratory用フォルダ内に作成してみたいと思います。
データベース名は…今後Amazonのデータを取得して構築すると仮定してます(*’ω’*)
まずはデータベースの保存先のパスを取得しましょう。
やり方は目的のファイル上で右クリック
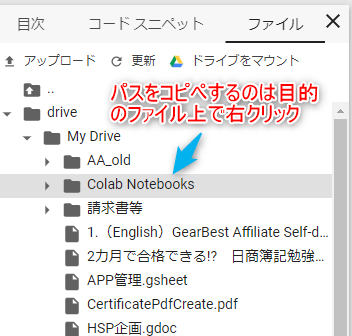
出てきたメニューにある「パスをコピー」をクリック
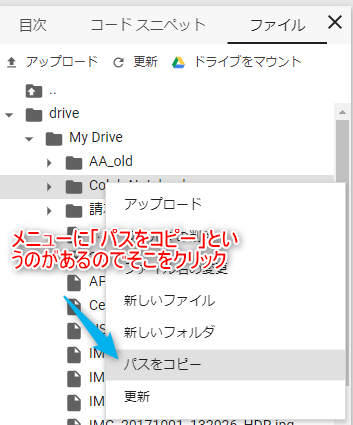
あとはColaboratoryのエディターに戻って貼り付けます。
今回はdrive_pathに入れておきます。
注意点としては、パスの最後にスラッシュを追加しているぐらいですかね。
続いてファイル名(こちらはdb_nameとしました)
ファイル名自体はお好みでOKですよ(*’ω’*)
データベースファイルを作成
ではさっそくデータベースファイルを作ってみましょう~意外と簡単です。
書き方は
sqlite3.connect(ファイル名)
なんですが、該当するファイルが存在しない場合には新規で作成してくれます。
これは簡単(*’ω’*)
ということで、下記のような感じに記述して実行します

すると…ファイルの方に
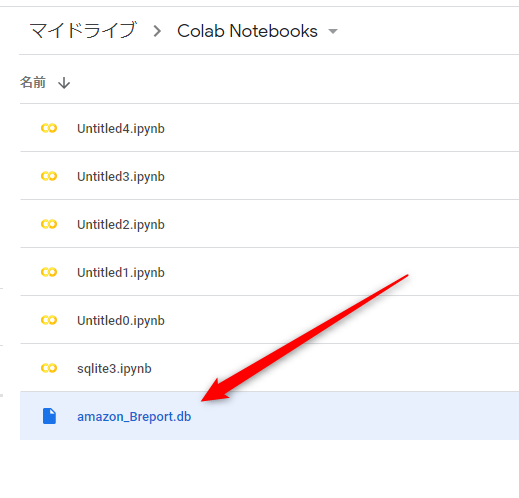
ファイルが出来てますね(*’ω’*)
まとめ
今回はここまでにします。
意外と簡単でしょ? ファイルを作成するまでですが(*´Д`)
この先、データを登録して、それを取り出す方法を書いていければと思っています。
仕事の合間に進めているので気長にお待ちください(;´・ω・)
参考になれば幸いです!