前回…といっても間はあいているのですが(;´・ω・)

Yahoo! ショッピングのランキング取得をpython+webAPIでやってみたので、今回は楽天版を考えてみたいと思います。
まずは準備
必要なのは
- 楽天のIDとパスワード(つまり、会員登録をするってことですね(*’ω’*))
- webAPI(developerページ)からアプリIDの発行をする(これによってAPIを使用するためのIDが取得できる)
といったところです。
まずは楽天の会員登録を済ませます。(https://www.rakuten.co.jp/)
登録したらログインした状態にしましょう。
次にdeveloperのページ(https://webservice.rakuten.co.jp/document/)から
アプリID発行をクリック(画面右上あたり)
遷移したページで情報を入力します。
アプリ名やアプリURLはひとまずのところ架空のものでOKだと思います。
(実際に公開するようなものの場合は、キッチリとしたURLなどが必要だとは思いますが)
- アプリ名:楽天ランキング取得
- アプリURL:https://example.com
というような感じでOK
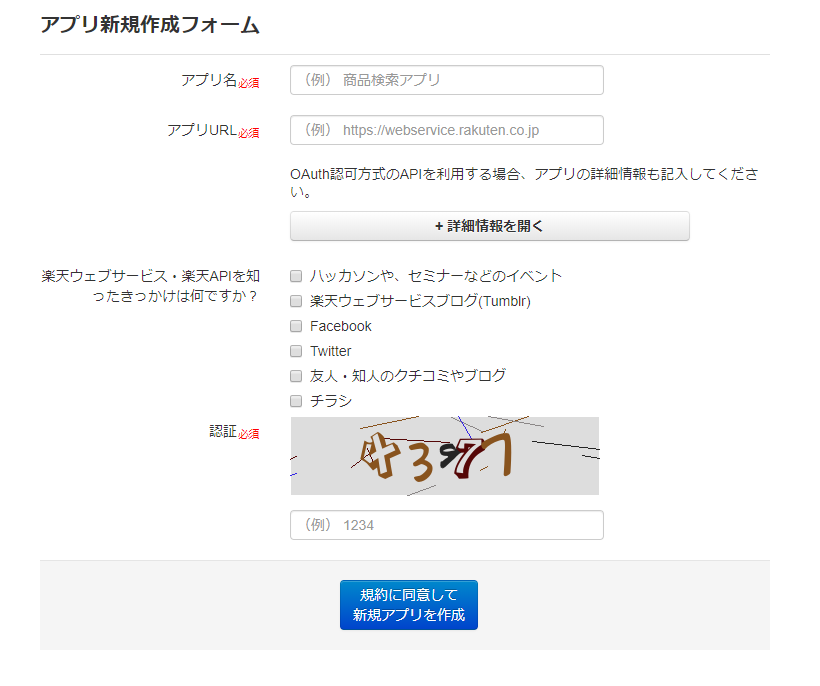
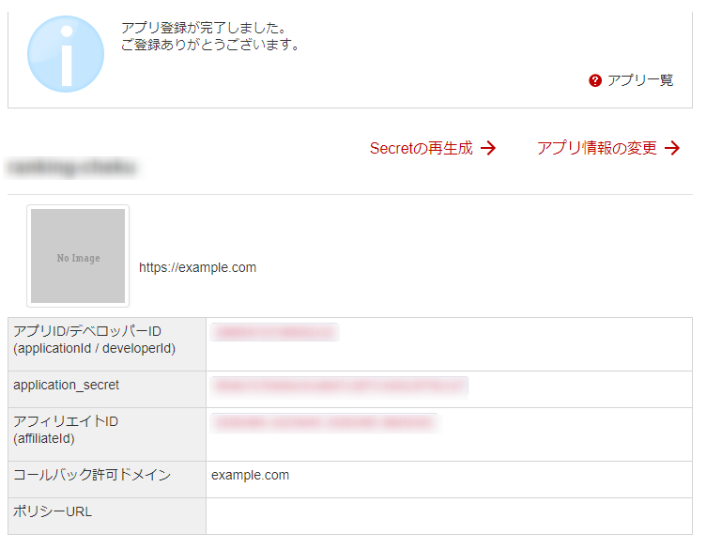
新規アプリを作成をクリックするとアプリIDなどが付与されます。
これをコピペなどで記録(保存)しておきましょ~(*’ω’*)
ランキングAPIのページをチェック
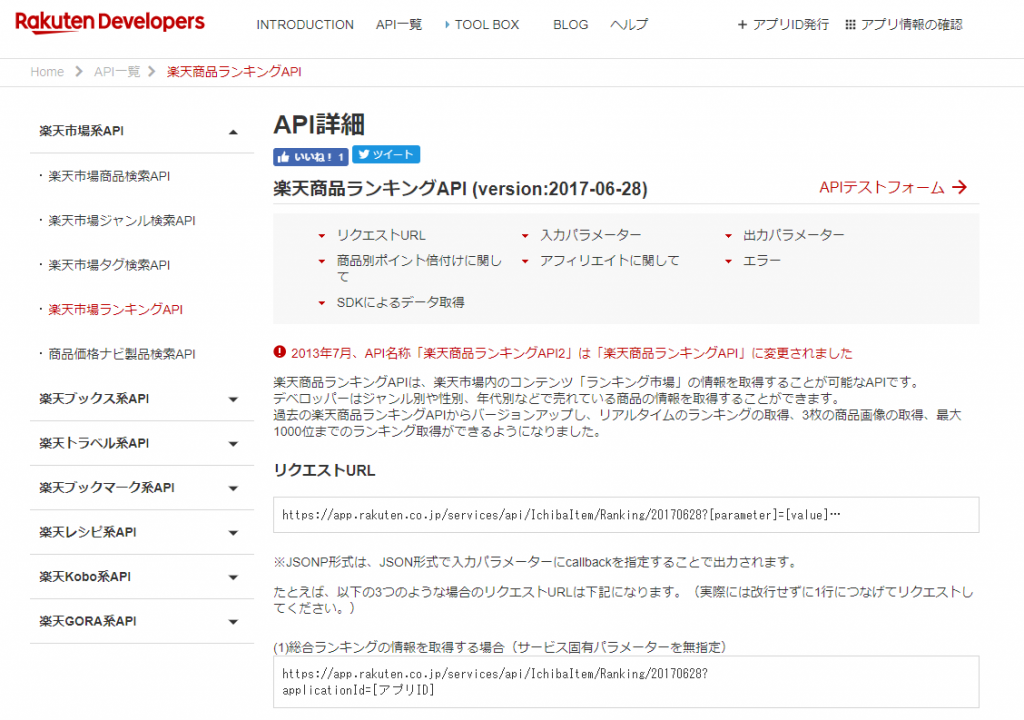
https://webservice.rakuten.co.jp/api/ichibaitemranking/
ページをよーく読んでみましょう~
まず情報をリクエストするURLは
- リクエストURL
https://app.rakuten.co.jp/services/api/IchibaItem/Ranking/20170628
これは特に問題ないですよね(*’ω’*)
次にパラメータ関連。
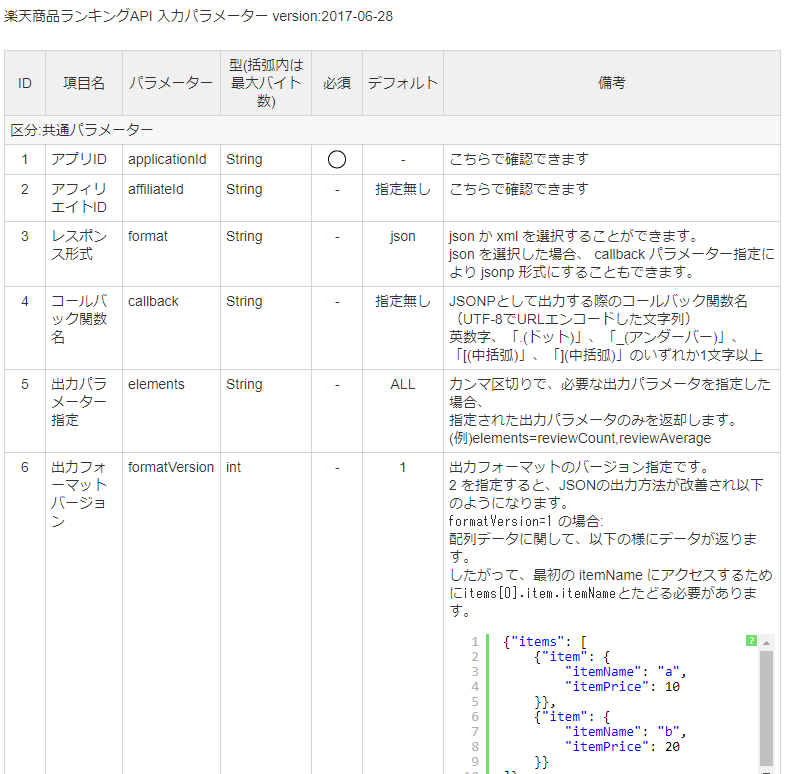
必要になるのが先ほど取得したアプリID(applicationId)。
出力データを扱いやすくするために出力フォーマットバージョン(formatVersion)を2に設定。
最後に一度に取得できるのが30位までになっているようなので、31位以下を取得するために取得ページ(page)を設定しましょう。
categoryは任意で(今回はスマートフォン本体)。
プログラム開始!
まずはインポートを設定。
今回使うのは
上記の5つ。
pprintなどはチェック用に入れてあるだけなのでいらないかもですが(;´・ω・)
- pandas:データの処理用(CSV出力など)
- numpy:行列入れ替えに(機械学習などではよく出てきます)
- requests:httpなど通信をするために
- json:jsonデータの処理用
次にパラメータをそれぞれ初期設定しましょう。
api_id = “先ほど取得したIDをコピペ”
category_num = “564500”
format_num = “2”
page_num = “1”
取得するランキングはスマートフォンに設定(category:564500)してます。
この後のプログラムイメージは
- 1回の取得は最大30位までなので、80位ぐらいまで取得するためには3ページ目まで繰り返し取得する必要がある
- 中途半端でランキングが終わっている場合はエラー処理をしてプログラムを止めないようにする
- 取得したデータは辞書形式にして整え、最終的にCSVとして出力する
という感じです。
次。
取得したデータを入れるために「result」を用意、さらにプログラム全体を3回繰り返すのでfor文をrangeを用いて3回繰り返す(ページ数として)。
ページ数はforの繰り返しの回数なのですが、for文の3回は0,1,2という数字の動きになるので、これを1,2,3に変えてあげる。
そしてそれぞれのパラメータを付け加えてリクエストを出す。
そのjsonデータを格納しておく。
※実際にはfor文の中身なので、インデントして書かれています。
30位ごとのデータなのでそれをひとつずつ取り出していきます。
その際、データがない場合などエラー処理を考えておきましょう。
必要なデータを取得していきます。
取得したら辞書形式での格納。
次にエラー時の処理ですが、for文から抜け出す形で問題ないと思うのでbreakでOKだと思います。
エラーは
- IndexError
- KeyError
のふたつ。
インデックスがないか、キーがみつからないかどちらかでしょうからね(*’ω’*)
※ブレイク部分は実際にはインデント処理してますのでご注意
最後にデータを処理し、CSV形式で保存。
そのままだと行にランキング(順位)が来てしまうので、行と列を入れ替えています(.Tの部分)。
文字化け防止用にエンコードも設定。
ざっと説明してきましたがこんな感じでデータが取得できるはずです。
プログラムはここからダウンロードできます(*’ω’*)
まとめ
いかがでしたか?
今回は急ぎ足で解説まで書いたので分かりにくい部分もあるかと思います(;´・ω・)
いずれにせよ、
簡単にプログラミングでデータ取得~出力までできる
っていうのを体感してほしいわけで(*’ω’*)
興味があるかたは是非ためしてみてください。
実際にColaboratoryで実行可能ですよ?
https://colab.research.google.com/notebooks/welcome.ipynb#scrollTo=xitplqMNk_Hc
※ただ、楽天側のデータ処理のせいなのか、取得データのパブリッシュ日時がずれていたりするので注意してください。
何かの参考になれば幸いです!