前回、スクレイピングの予告みたいなものをしました。

え、今回まずは最初の段階としてhtmlを取得してみようかと。
とにかくシンプルで扱いやすい設計というPythonですから…取得自体も実に簡単にできちゃったりします。
まずは準備
準備ということで、必要なモノをインストールしておきます。
Anacondaをインストールした際に、プロンプト(prompt)も実行できるようになっています。
プログラムから探してみると「Anaconda Prompt」があると思います(画面はwin10)。
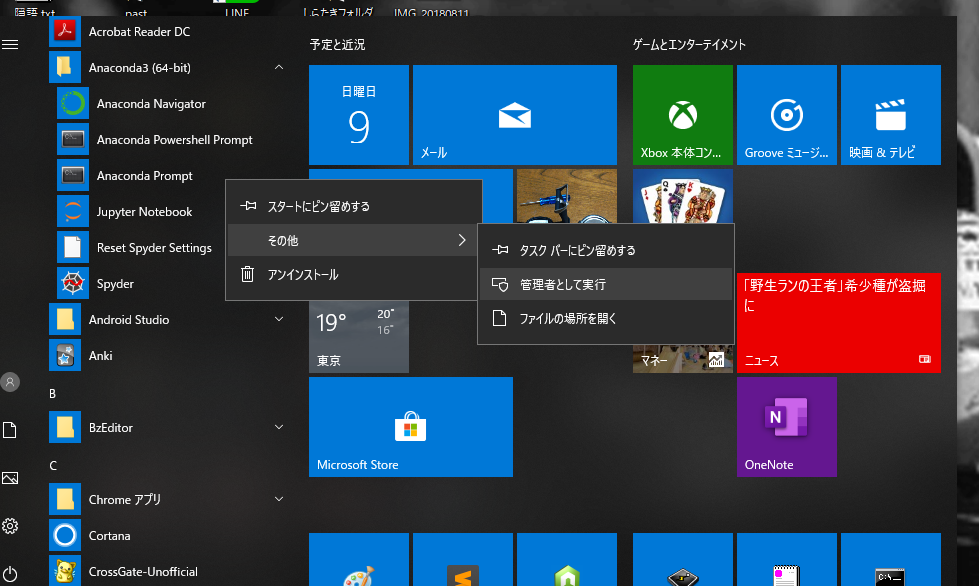
みつけたら、右クリックで「その他」「管理者として実行」を選びます。
プロンプトが立ち上がったら
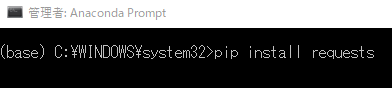
- pip install requests
と打ち込んでエンター。
この「requests」を利用してhtmlをゲットすることになります(*’ω’*)
…で、実際に実行してみたら
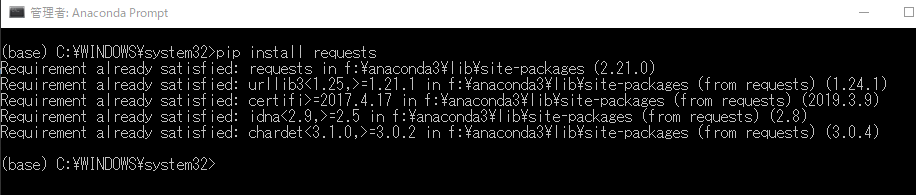
ん? なにやらすでにあるっぽいという反応(;´・ω・)
ちゃんと翻訳してみると
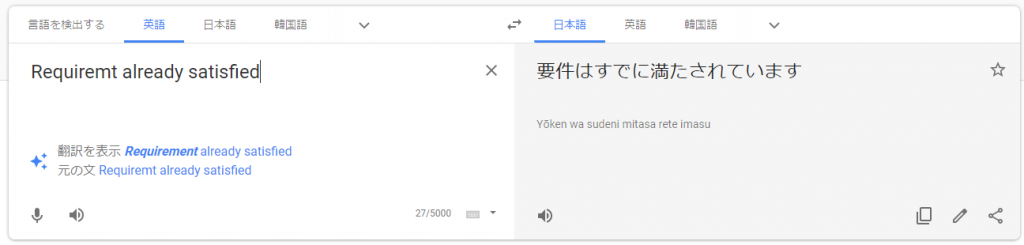
やっぱりね。
どうやらAnacondaではパッケージされている様子。
ま、一応念のためにインストールコマンドを実行してみてくださいね。
実に簡単、たったの3行
まずはrequestsを利用するためにimportを実行します
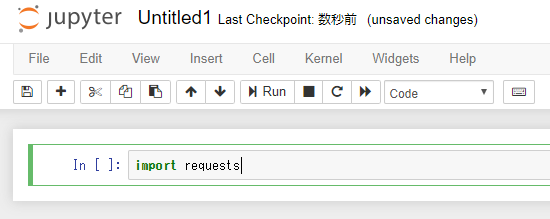
実行しても特に変化はないと思います(実行は「Ctrl+エンター」)。
次にrequestsの使い方。
変数を用意してrequest.get()を実行、()の中身にはアドレスを入れます。
ここでは自分のページ(https://tks-kan.com/)にしてみます。
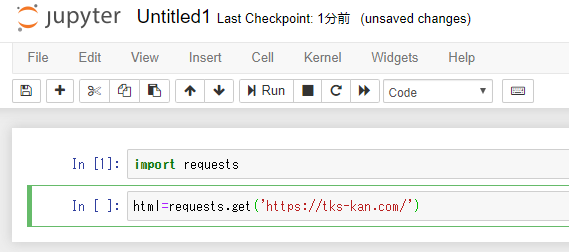
これを実行してみると…
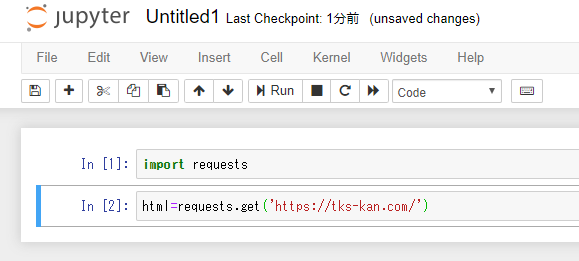
実は特に変化はないんです。
でも、htmlに中身が入っているはずなので、これを表示させてみましょう(*’ω’*)
print()を使ってみます。
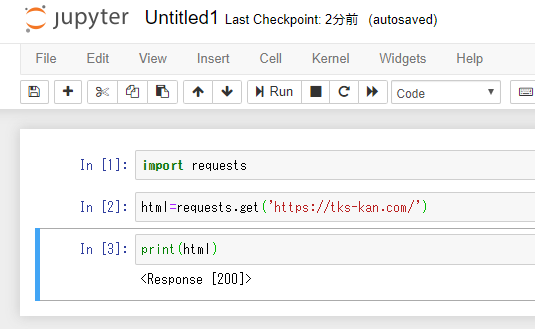
およ?
response [200] ってことは、HTTPのステータスコードが入っているようですな(;´・ω・)
……。
どうやら、htmlは「.text」を付けてあげないといけないようです。
ということで「print(html.text)」で実行しなおしてみると
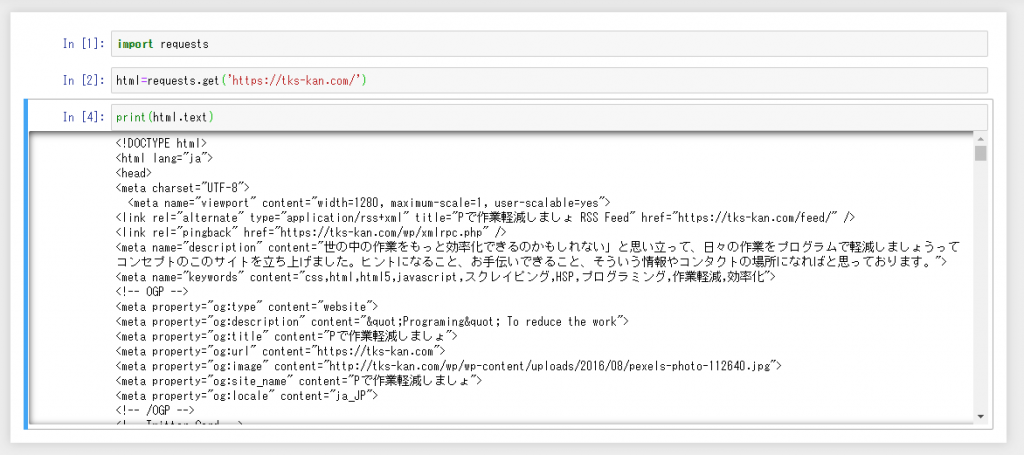
おぉ、ちゃんと取り出せてますね!
htmlがたった3行で取得出来ちゃいました。
html=requests.get(‘https://tks-kan.com/’)
print(html.text)
これだけですからねぇ~こりゃお手軽です。
まとめ
いかがでしたか?
これなら簡単に扱えそうですよね(*’ω’*)
もちろん、取得できない場合の処理とか、解析するためにはファイルとして保存もしなきゃいけないわけですが…それを考えてもこの手軽さはいいですね。
次回も引き続きスクレイピングに挑戦していく予定です。
何かの参考になれば幸いです!