GASでのスクレイピングについては前回まででほぼ基本的なことは出来たと考えています(*’ω’*)
が、しかし。
スプレッドシートでスクレイピング といったキーワードで検索するとよく出てくるものに触れていないのもいかがなものかと思った次第。
…というよりも、使い方がイマイチわかってないのが本当のところなんですが(;´・ω・)
ここでの目標は「その8」で取得した結果と同じようなものを取り出せればいいかなと思っています。
つまり、
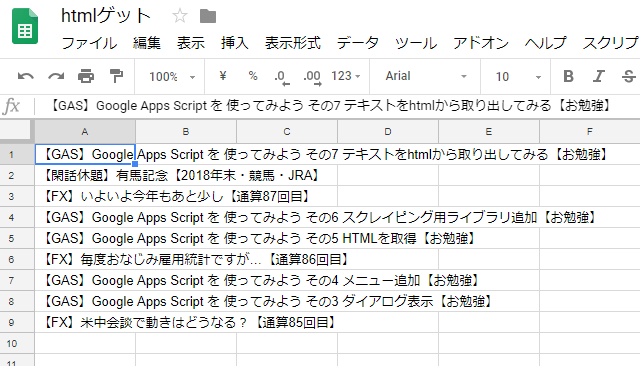
- このブログの記事タイトル(トップページのみ)一覧
です。



IMPORTXMLの使い方、書式
検索するとこれをつかって簡単スクレイピングみたいなものをたくさんみかけますよね。
スプレッドシートのひとつのセルに
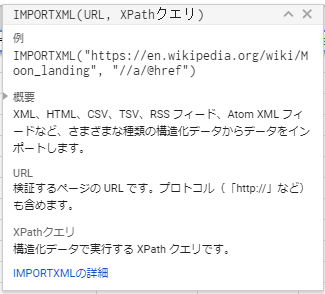
=IMPORTXML(“[URL]”,”[取り出したい場所のXPATH]”)
と、これだけで目的にモノが取り出せるって書いてあったりします。
XPathも簡単に分かる…はずなのに?
さらに続けて「えー、XPATHなんてわからんよ~ って方も大丈夫」みたいなパターンで「chromeのデベロッパーツールを使うと簡単にXPATHが取得できるよ」と。
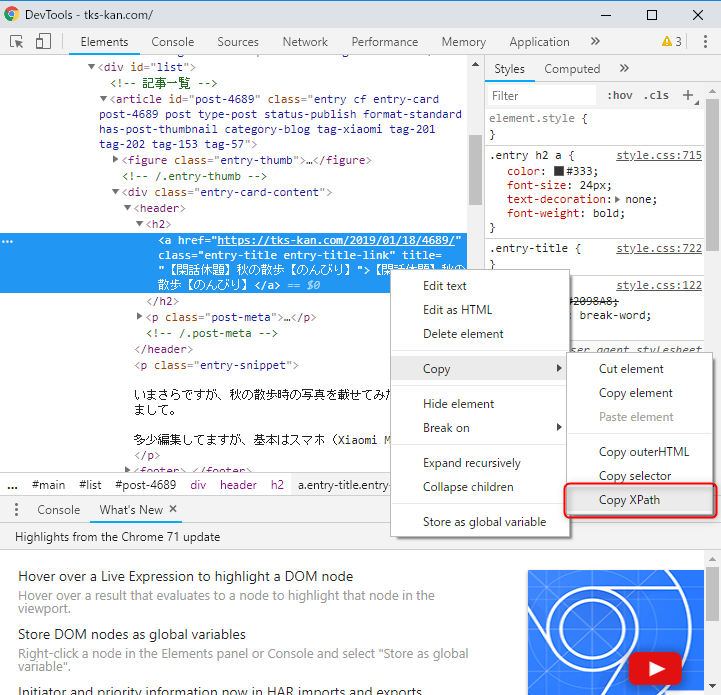
たしかに「Copy XPath」とあるので、取得は簡単にできそうです(*’ω’*)
が、しかし(二回目)。
実際に取り出せたXPathは「//*[@id=”post-4689″]/div/header/h2/a」というもの。
これをダブルクォーテーションの部分をシングルクォーテーションに変更してIMPORTXMLに入れてみても…
=IMPORTXML(“https://tks-kan.com/”,“//*[@id=’post-4689′]/div/header/h2/a”)
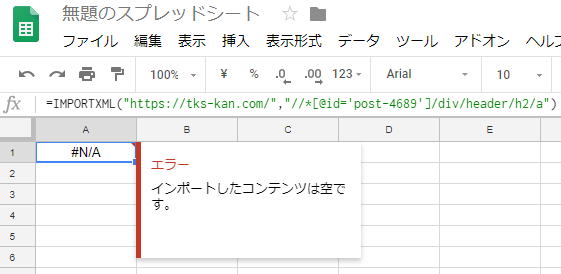
う~ん、正直、これで悩んでました。
XPath的に間違っているとは思えないので(コピペですしねw)、もうわけわからないって感じで。
ふと思いついたXPathに変えてみると…?
XPathについて調べてみたりしていると、idだけ(@id=”)じゃなくて
タグ名[@class=”]
みたいなクラス名での書き方もある。。。これだと、該当するクラスのものを全部取り出せそうな予感。
自分のサイトのhtmlをみてみると(取り出したいタイトル部分のhtmlですね)
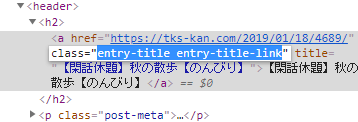
クラス名「entry-title entry-title-link」で指定できそうですよね。
タグ名は「a」なので
=IMPORTXML(“https://tks-kan.com/”,”//a[@class=’entry-title entry-title-link’]”)
これで出来なかったら諦めじゃね?(*´Д`)
という気持ちでやってみると
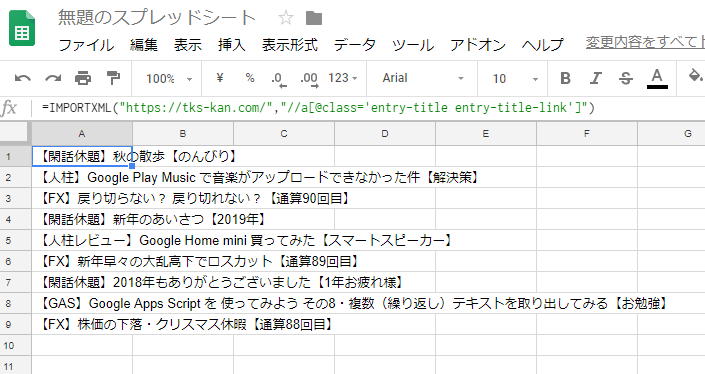
わお! あっさりと取り出せたw
デベロッパーツールでのコピペで出来ずに、自分で考えたら出来る…うーん、こういうこともあるわけですなぁ。
というわけで。
拍子抜けに同じような結果を再現することができちゃいましたので、ちょっと他にも試してみたくなり、楽天の検索結果から値段だけをスクレイピングで取り出してみることに。
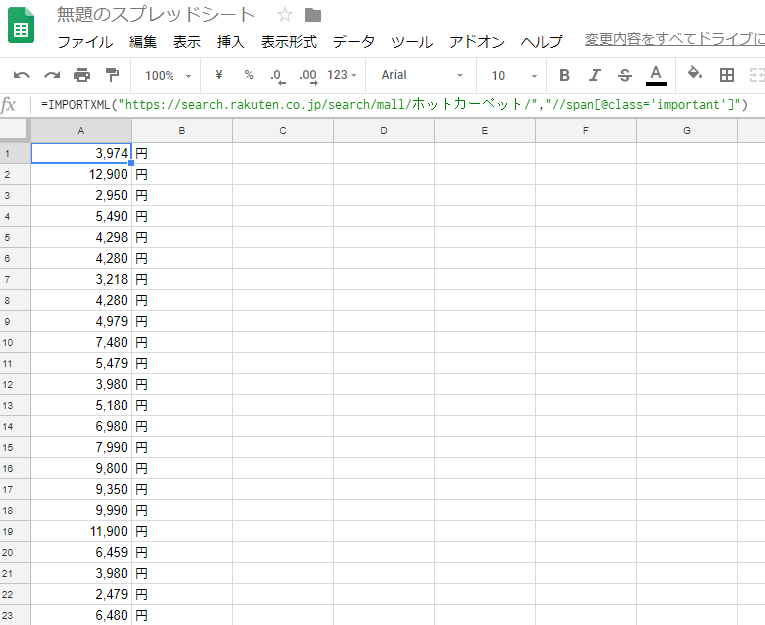
いけた、いけた。
ちなみに、こんな感じの記述です。
=IMPORTXML(“https://search.rakuten.co.jp/search/mall/ホットカーペット/”,“//span[@class=’important’]”)
該当する値段の部分のクラス名が「important」だったので、上記のようなコードに。
たしかにこれは楽ちんですね(*’ω’*)
まとめ
ずっとうまくXPathが指定できなくて悩んでたんですよね。
だからこそしっかりスクレイピングしてみようと考えになったわけでして>GASでね
なので、意外に長い期間試行錯誤してたりしてました。
でもこれでやっと解決しましたよ(*´Д`)
何かの参考になれば幸いです!