HSPでのスクレイピングは主にF1のポイントランキングで記事として書いていたんですが、業務などでも使ったりしています。
すると、ページによっては凄く時間がかかることがあったりします。
その原因は…
- 大量の行数あるhtmlである
- それを頭から1行1行チェックしている
という流れにありました。
仮に1万行あったとして、1行0.1秒で処理できたとしても1000秒はかかるわけです。
実際にはもっともっと速い処理をしてくれているんですけど、実際にはそれを200ページぐらい処理することになると、時間がかかってしまう理由が分かってもらえるかと(*’ω’*)
どうしたら処理時間が短縮になる?
一番いいのは
- 取り出したい情報が書かれている行がどこかわかっている
- しかもそれは行番号などが固定である
こうなれば、その行だけを処理するのは簡単。
その行を指定して抜き出して、情報部分を抜き出すようにすればOK(*’ω’*)
でも、なかなかそう簡単には処理できないのが現実。
次に考えたのは
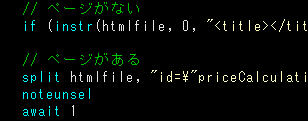
- 行番号が固定化していないなら、その少し手前であり、かつ絶対に取り出したい情報がそれ以前に出てこない部分でhtmlファイルを分割する
この方法なら、まあまあ時間短縮は可能だし、半分以上が要らないだった場合は単純に処理時間が半分程度に減るはず。
次に思いついたのは
- 取り出したい情報の近くに「そのhtml内で唯一ひとつの単語がないか」を探し出す
でした。
これによって分割するポイントが固定じゃなくても可能になるわけです。
しかも取り出したい情報に近ければ近いほど処理の時間が短くなる利点もあります。
ということで、現在は一番最後の方法を利用して200ページ以上の処理をしてます。
しかもプログラムを実行させておくだけなので、その時間は別の作業にあてられるのが大きいわけで(*’ω’*)
まとめ
今回は考え方というかアプローチ方法というかアイデアを紹介してみました。
ちなみに、半日近くかかっていた処理ですが、今は1時間もかからない状態で情報を集められています(*’ω’*)
コピペだらけで腱鞘炎になったりもしないで済んでますしね~
あまりプログラムと関係ないかもしれませんが…参考になれば幸いです。