いよいよ本をみながら学習開始。
作業フォルダを無駄に多いドライブのGに決定。フォルダを作成し、その名を「node_study」とした。エディタは、使い慣れているsublime textを使用していくことにする。とはいえ、学習用のPCにはインストールしていないので、改めてダウンロードをして設定。
※パッケージコントローラーや日本語化、各種パッケージインストールについては割愛します。
さっそく2章01のプログラムを打ち込んで実行
ファイル名を間違えるポカミスをしたものの、無事実行できた。test.htmlもちゃんと出来てた。つづく、ブラッシュアップ版もconsole.logのスペルを間違えた以外は問題なく終了。リダイレクト云々の部分はページが移動しました的なページに変わってた模様。結果は違っていたけども、とりあえず無事に完了。続くrhinoの部分は省略してみる。環境構築してまで試したい部分でも無かったので…。
2章の02「HTMLの解析(リンクと画像の抽出)を学習
解析ということで、見出しにスクレイピングの文字。以前、phpや他の言語、もちろんjavascriptでも軽く経験している部分。nodeでどういう感じに解析していくのか興味のある部分でもある。
モジュールはcheerio-httpcliを使用するとのこと。ファイルのダウンロードやjQueryライクで要素を取り出せるみたいですね。npmを使用して、作業フォルダ「2_02html」にてインストールする。
npm install cheerio-httpcli
続いてプログラムだが、基本的にダウンロードせずにsublime textを使って打ち込んでみる(なんだか昔のベーマガ片手にポチポチとキーボードをたたいている気分)。
さて、「htmlファイルをダウンロードしてみよう」というプログラム実行結果も問題なかったのだが、このcheerio-httpcliというモジュールにあるfetch()メソッドがどういうものなのか調べてみようと思う。
モジュールの中にあるcore.jsから抜粋。
fetch: function (url, param, encode, callback) {
return client.run('GET', url, param, encode, callback);
},
/*
*
* GETによる同期httpリクエストを実行
*
* @param url リクエスト先のURL
* @param param リクエストパラメータ
* @param encode 取得先のHTMLのエンコーディング(default: 自動判定)
* @param callback リクエスト完了時のコールバック関数(err, cheerio, response, body)
*/
ふむ。これを見る限り、本に載っているプログラムにある
client.fetch(url, param, function(err, $, res){
を以下に変更
client.fetch(url, param, function(err, $, res, body){
さらに
var body = $.html();
をコメントアウトして
// var body = $.html();
実行してみると…結果は同じものを得られた。
本の書かれていた時期からモジュールがバージョンアップしていたのか、それともちゃんと結果からbody部分と取り出す書き方を「わざわざ」やっているのか定かじゃないが、ひとまずメソッドでどうなっているのか調べるときにはモジュールの中を調べれば少しは理解できそうである。
ちなみに、検索したところ以下のページも見つかった。作者さんだろうか?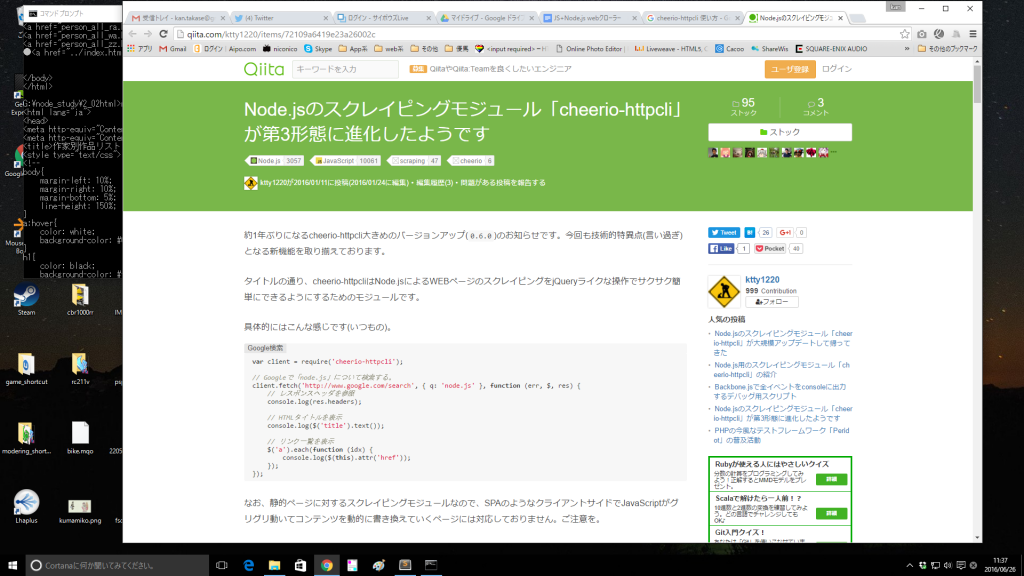
Node.jsのスクレイピングモジュール「cheerio-httpcli」が第3形態に進化したようです
「htmlファイルのリンクを抽出してみよう」にすすむ
本によると「このモジュールの特徴として、webからHTMLを取得した後、内容を解析して、CSSのセレクタで任意の要素を検索できるという機能があります」なんて記述がある。スクレイピングっぽい文言だが、HTMLやCSSをいじったことがない人にとってはなんのこっちゃって感じだろうなあ。
まあ、HTMLから情報を取り出すときに便利な方法があるんだぜ! みたいなニュアンスで考えればいいんじゃないかな。いずれにせよ、web(htmlなど)の知識がないとダメなんだけども。
ポイントは以下の部分。
// リンクを抽出して表示
$("a").each(function(idx) {
var text = $(this).text();
var href = $(this).attr('href');
console.log(text + ":" + href);
});
$(“a”)でaタグを拾い出し、each(function(idx) {}の中のtext();でテキストの部分(たぶんinnerText)、attr(‘href’);でhrefの中身を取り出している。
「相対URLを絶対URLに変換しよう」へ
urlモジュールを使うことで、../や/で書かれる相対パスを絶対パスに変換してくれる。
// モジュールの読み込み
var URL = require('url');
var base = "http://kujirahand.com/url/test/index.html";
var u1 = URL.resolve(base, 'a.html');
console.log('u1 =' + u1);
urlモジュールのresolve()メソッドにて変換する。これをさっきのURL抽出に組み込んで処理すると、絶対パスの取得完了。
「画像ファイルを抽出してみよう」
ここで使うのはwikipediaの犬。猫派なんだけどなぁ。ま、それはそれ。imgタグの取り出し、src属性でしている画像ファイルの一覧を表示する。しかし、どうも本のまま(wikiから)の取得はエラーになるっぽいことがわかったので、別のurlにて試してみることで、無事errorを吐かずに実行できた。
次に画像をダウンロードするためのrequestモジュールを追加する。npmでインストール。
npm install request
これによって簡単にダウンロードできるようになるみたいなのだが、その説明はほどんとなかった。命令としては一文
request(url).pipe(fs.createWriteStream(savepath));
これでhtmlがダウンロードできてしまうとのこと。もちろん、urlやsavepathの部分は事前に設定しておく必要があるのだが。
では、実際に画像をダウンロードするプログラムを打ち込んでみる。ここでのポイントは以下の二つ。
- 保存先のフォルダを作成する、その際、フォルダの有無を確認して無ければという処理。さらに、非同期ではなく同期型にして、フォルダが作成されるまで処理を待つという状態にするこで、先に画像をダウンロードしてしまう流れになってしまった際に保存先が存在しないという状況を未然に防いでいる。命令としてはfs.mkdirSync();。フォルダの有無判断も同期型でfs.existsSync();。
- 相対パスを絶対パスに変換後、そのURLからパス名を取り出して保存用の名前とする。その際、スラッシュ(/)がファイル名としては使えないことからも、正規表現を用いて、アルファベット、数字、ドット以外のものをアンダーバーに変換(replace)させている。保存の部分については上記にだした一文と同様。HTMLだろうと画像だろうと基本的にファイルの保存という点では同じだから。
以下にプログラムの抜粋を。
// 保存用のファイル名を作成 var fname = URL.parse(src).pathname; fname = savedir + "/" + fname.replace(/[^~a-zA-Z0-9\.]+/g, '_'); // ダウンロード request(src).pipe(fs.createWriteStream(fname));
今回はここまで
ログとして書いていたので読ませる文章として、もっと修正が必要な気もしてます。おいおい編集していくかもしれません。。。