前回、レース結果ページからのデータ取得はクリアできたので今回は2016年版のレース結果URLの自動取得およびデータの保存に取り掛かってみようと思います。目標としては
- プログラムを実行すると自動的にレース結果のURLを取得する
- URLの取得は今まで取得していなかったもののみ
- 取得したURLデータをなんらかの形式でデータ保存しておく(参照する為に)
- 2016年版で実行してみて、2017年版にフィードバックする
という感じで進めていきます。まあ、つまり「実行したら特に操作することなくURLをコレクションしたいな」って思惑です。
URL抽出条件の確認
レース結果のURL抽出は「2017年版その2」にて調べています。

データ抽出対象のページは
https://www.formula1.com/en/results.html/2016/races.html
aタグを抽出するためのクラス名は
- クラス名 「dark bold ArchiveLink」
でした。
データ抽出対象ページをダウンロードする
以前のコードを利用してなるべく手間を減らすのも、このシリーズの隠されたテーマだったりします(ものぐさなだけなのですがw)。ということで、前回のプログラムを改造しながらすすめていきます。まず、ダウンロード対象のURLを設定。
download_url = "https://www.formula1.com/en/results.html/2016/races.html"

取り出すURLを格納しておく入れ物を用意します。URLの文字数がものすごく長くなることはないとは思いますが、念のため半角200文字分の容量を指定しておきます。数は40個。
sdim geturl, 200, 40
![]()
ほかは特に修正しなくても大丈夫だと思います。念のためにここまでのコード。
//HSPモジュール SAKMISさんのを使用しています
//命令→lfcc ファイルネーム
//読み込み→改行置換→保存
#module
#deffunc lfcc str filename
; mref filename,32
; mref status,64
exist filename
size=strsize
if size=-1 : status=-1 : return
sdim ss,size+1,1
bload filename,ss,size
ii=0
code=0
sdim data,size<<1,1
repeat size
tt = peek (ss,cnt)
if tt=10 : code=10 : break
if tt=13 {
code=13
tt = peek (ss,cnt+1)
if tt=10 : code=0
break
}
loop
if code=0 : status=-1 : return
repeat size
tt = peek (ss,cnt)
if tt=code : wpoke data,ii,2573 : ii+2 : continue
poke data,ii,tt : ii++
loop
bsave filename,data,ii
status=ii
return
#global
#include "hspinet.as"
// ネット接続の確認
netinit
if stat : dialog "ネット接続できません" : end
// 初期設定
// download_url = "https://www.formula1.com/en/results.html/2017/drivers.html"
// download_url = "https://www.formula1.com/en/results.html/2016/races/938/australia/race-result.html"
download_url = "https://www.formula1.com/en/results.html/2016/races.html"
sdim firstname, 40, 40
sdim familyname, 40, 40
sdim country, 40, 40
sdim teamname, 40, 40
sdim getpoint, 40, 40
// 追加したもの
sdim position, 40, 40
sdim carnumber, 40, 40
sdim laps, 40, 40
sdim times, 40, 40
sdim geturl, 200, 40
/* 第一回で作成したダウンロード部分 */
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
neturl url_address
netrequest url_pagename
*main
//取得待ち確認
netexec res
if res > 0 : goto *comp
if res < 0 : goto *bad
await 50
goto *main
*bad
//エラー
neterror estr
mes "ERROR "+estr
stop
*comp
mes "DOWNLOAD 完了"
stop
これを実行すると「races.html」というファイルが生成されます。ブラウザで確認してみると
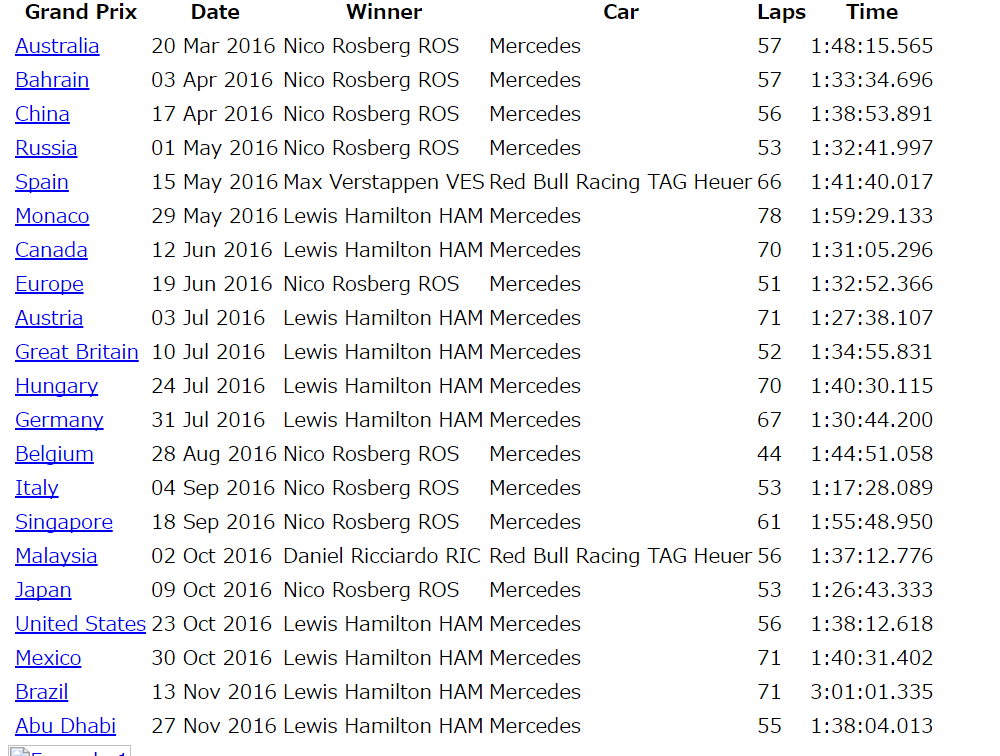
無事ダウンロードできたようです。
ダウンロードしたファイルを使ってデータ抽出部分の作成
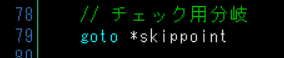
実行するたびにダウンロードするのも気が引けるので、今保存したファイルを活用しましょう。まず、ダウンロード部分を回避する為に以下の命令を追加します。
// チェック用分岐 goto *skippoint
次にデータ抽出部分に上で設定したチェック用のラベルを追加します。
*skippoint //チェック用ラベル

さて、クラス名を用いてデータの抽出に取り掛かります。「dark bold ArchiveLink」ということなので、以下のようにコードを記述します。
url_cnt = 0
repeat notemax
noteget text_line, cnt
// RACE_URL
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
(ここで不要なものを排除してURLのみを抽出する)
}
loop
「dark bold ArchiveLink」が1文内にヒットしたら、URLを抽出するという流れですね。
次にダウンロードしたファイルからURL部分を引っ張り出してみます。
<a href="/en/results.html/2016/races/938/australia/race-result.html" data-ajax-url="/content/fom-website/en/results/jcr:content/resultsarchive.html/2016/races/938/australia/race-result.html" class="dark bold ArchiveLink">
すべてがこのパターンで書かれているならsplitをつかって「”」を基準に分けてしまうのが楽そうですね。ということで
repeat notemax
noteget text_line, cnt
// RACE_URL
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
split text_line, "\"", buf
geturl(url_cnt) = buf(1)
url_cnt++
}
loop
としてみました。実際に取り出せているか確認するために
dialog geturl(0)
をloop以下に記述してテストしてみます。
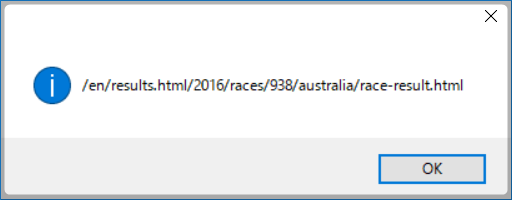
バッチリ取り出せてますね。
どのレースのURLなのかをわかりやすくする
あとで「どのURLだったっけ?」というのをなくすためにも、予めグランプリ名とURLを対応させておきます。そのためには
- グランプリ名を取り出す
- 格納しておく入れ物を用意する
が必要ですね。入れ物は
sdim gpname, 200, 40
としました。グランプリ名は実はaタグの次の行に書かれているようなので
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
split text_line, "\"", buf
geturl(url_cnt) = buf(1)
url_cnt++
}
ここのif文に
noteget gpname(url_cnt), cnt+1 strrep gpname(url_cnt), " ", "" gpname(url_cnt) += " GP result"
を追加します。確認は
dialog gpname(url_cnt)
で、結果は
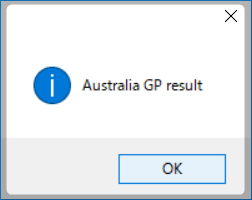
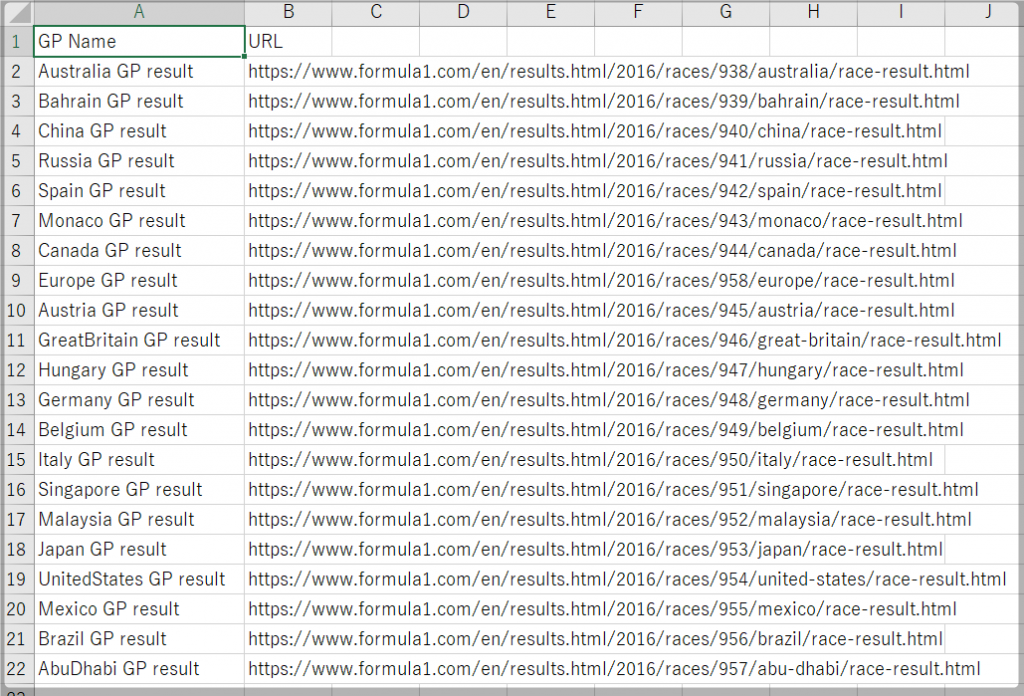
取り出せました。これをcsv形式にして出力したいと思います。コードは以下みたいになりました。
//make_csv
csv_text = "GP Name,URL\n"
repeat 40
if gpname(cnt) = "" : break
csv_text += gpname(cnt) + ",https://www.formula1.com" + geturl(cnt) + "\n"
loop
// csv出力
notesel csv_text
notesave "Raceresulturl.csv"
noteunsel
await 1
dialog "save csv file"
並び順はグランプリ名、URLで、URLも相対から絶対に変更するためにアドレスを追加しています。これを実行して結果をみてみると
ちゃんと出来てますね!
まとめ
今回はここまでとします。ひとまずURLの抽出と対応するグランプリ名は取り出せて、CSV形式で保存もできました。次回は新しく追加されたグランプリの結果のみを追加するための考察をしていきたいと思います。コードを押せておきますので、興味のある方お試しくださいな。
//HSPモジュール SAKMISさんのを使用しています
//命令→lfcc ファイルネーム
//読み込み→改行置換→保存
#module
#deffunc lfcc str filename
; mref filename,32
; mref status,64
exist filename
size=strsize
if size=-1 : status=-1 : return
sdim ss,size+1,1
bload filename,ss,size
ii=0
code=0
sdim data,size<<1,1
repeat size
tt = peek (ss,cnt)
if tt=10 : code=10 : break
if tt=13 {
code=13
tt = peek (ss,cnt+1)
if tt=10 : code=0
break
}
loop
if code=0 : status=-1 : return
repeat size
tt = peek (ss,cnt)
if tt=code : wpoke data,ii,2573 : ii+2 : continue
poke data,ii,tt : ii++
loop
bsave filename,data,ii
status=ii
return
#global
#include "hspinet.as"
// ネット接続の確認
netinit
if stat : dialog "ネット接続できません" : end
// 初期設定
// download_url = "https://www.formula1.com/en/results.html/2017/drivers.html"
// download_url = "https://www.formula1.com/en/results.html/2016/races/938/australia/race-result.html"
download_url = "https://www.formula1.com/en/results.html/2016/races.html"
sdim firstname, 40, 40
sdim familyname, 40, 40
sdim country, 40, 40
sdim teamname, 40, 40
sdim getpoint, 40, 40
// 追加したもの
sdim position, 40, 40
sdim carnumber, 40, 40
sdim laps, 40, 40
sdim times, 40, 40
sdim geturl, 200, 40
sdim gpname, 200, 40
/* 第一回で作成したダウンロード部分 */
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
// チェック用分岐
goto *skippoint
neturl url_address
netrequest url_pagename
*main
//取得待ち確認
netexec res
if res > 0 : goto *comp
if res < 0 : goto *bad
await 50
goto *main
*bad
//エラー
neterror estr
mes "ERROR "+estr
stop
*comp
mes "DOWNLOAD 完了"
stop
/*html生成部分(2~5回で作成)*/
*skippoint //チェック用ラベル
// lfcc "drivers.html"
lfcc url_pagename
notesel htmlfile
// noteload "drivers.html"
noteload url_pagename
url_cnt = 0
repeat notemax
noteget text_line, cnt
// RACE_URL
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
split text_line, "\"", buf
geturl(url_cnt) = buf(1)
noteget gpname(url_cnt), cnt+1
strrep gpname(url_cnt), " ", ""
gpname(url_cnt) += " GP result"
url_cnt++
}
loop
//test
//dialog geturl(0)
//dialog gpname(0)
noteunsel
//make_csv
csv_text = "GP Name,URL\n"
repeat 40
if gpname(cnt) = "" : break
csv_text += gpname(cnt) + ",https://www.formula1.com" + geturl(cnt) + "\n"
loop
// csv出力
notesel csv_text
notesave "Raceresulturl.csv"
noteunsel
await 1
dialog "save csv file"
//mesbox html_text, 640, 400
end
stop