前回はHTMLの取得にチャレンジしてみました。

いよいよスクレイピングに向けての実践モードといった感じになってきたわけですが、前にも書いたように普通のDOM操作みたいなことは出来ないのが難点。
色々と調べていくとxmlのものや正規表現をつかって該当する部分を取り出すみたいなものが多くヒットしてきます。
でも、それだとなかなか応用をきかすのが難しいというか、それ専用の技みたいな感じになってしまって…あと、正規表現って使いだせば思い出してくるんですが普段はサッパリでして(;´・ω・)
何かいいものがないかなと検索をしていたら、よさげなページにヒット。
簡単データスクレイピング?
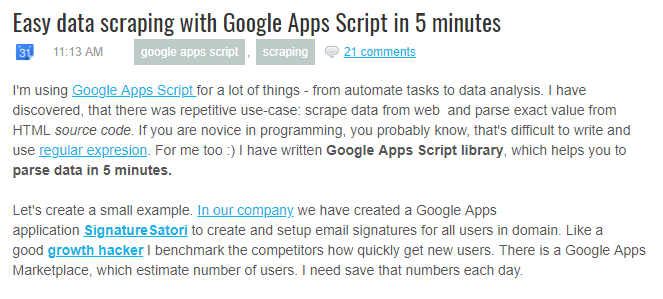
「イージーデータスクレイピング ウィズ GAS イン 5ミニッツ」
素敵な響きじゃないですか!
ちなみに翻訳してみると…
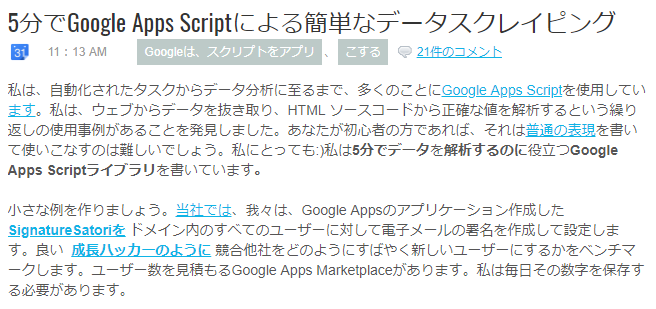
「私は、ウェブからデータを抜き取り、HTMLソースコードから正確な値を解析するという栗菓子の仕様事例があることを発見しました。(中略)5分でデータを解析するのに役立つGASライブラリを書いています」
おぉ、これは期待できそう。
ちなみにurlは
https://www.kutil.org/2016/01/easy-data-scrapping-with-google-apps.html
です。
ということで、さくっとライブラリを追加しちゃいましょう~!
…ところで、ライブラリ追加って何?
簡単でした、ライブラリの追加方法
ライブラリを追加することで、そのライブラリ独自のコード(命令?)を書くことが出来て、大体の場合、それは便利な機能になる…って感じかな。
今回のライブラリはスクレイピングに使える便利なものですよ。
使い方も簡単ですし(*’ω’*)
さて、追加の方法ですが、まずはスプレッドシートを開いてツールからスクリプトエディタを開きましょう。
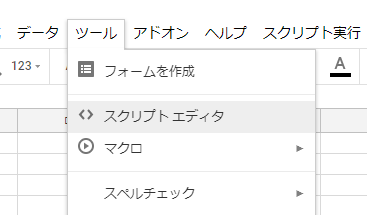
次にスクリプトエディタのリソースからライブラリを選択します。
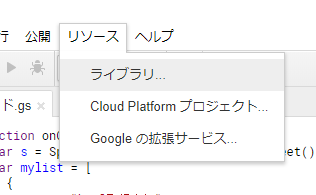
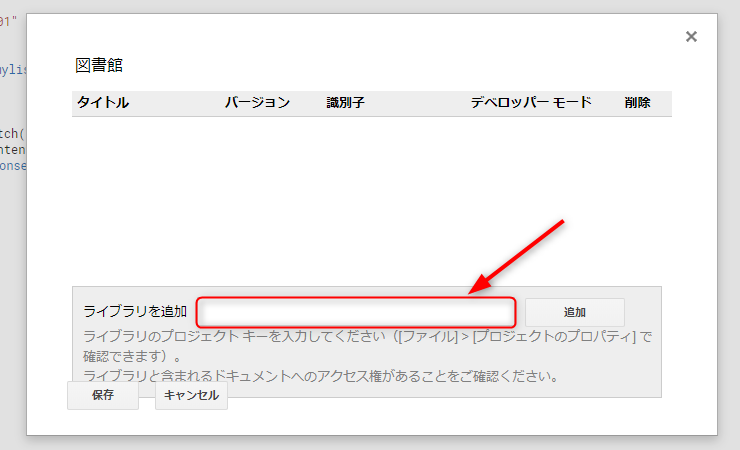
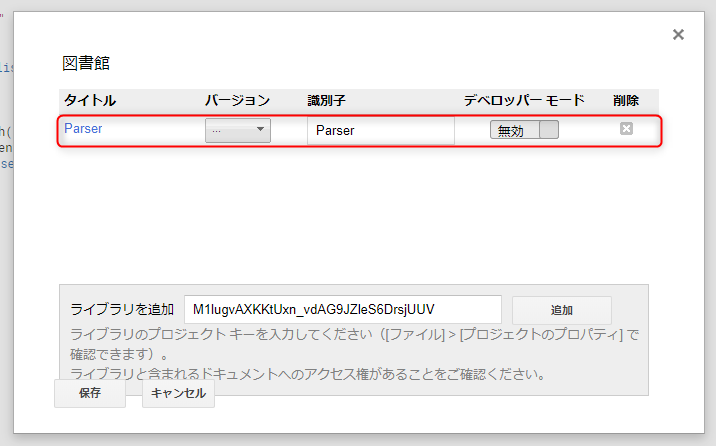
すると、「図書館」というダイアログが出てきます。
その中のライブラリを追加の隣にある入力部分に、ライブラリのプロジェクトキーを入力します(プロジェクトキーは先ほどのHPに載ってますよ~)。
プロジェクトキーを入力(コピペ)したら、追加をクリックします。
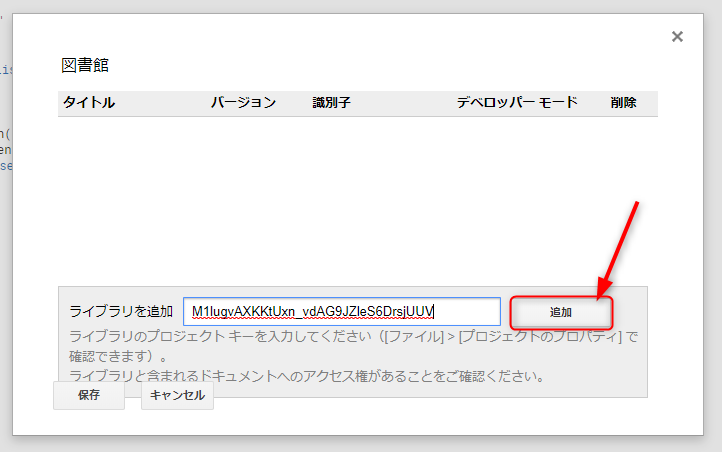
Parserというタイトルのライブラリが追加されました!
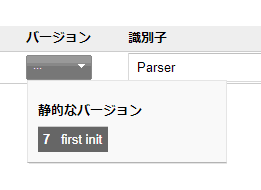
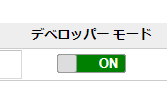
次にバージョンを最新のものに、デベロッパーモードをオンにしておきます。
それができたら、保存をクリックしましょう。
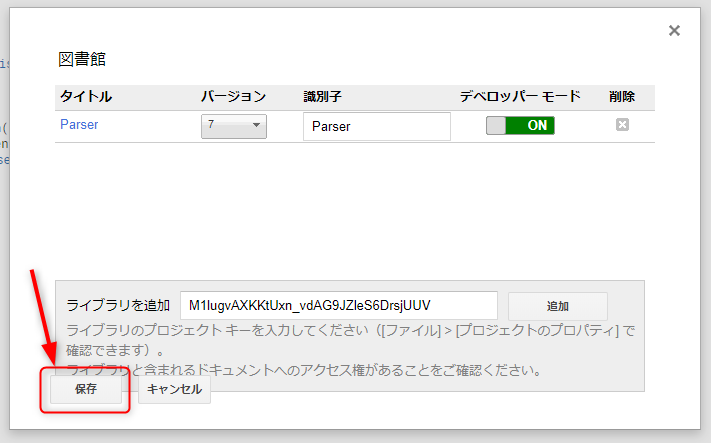
すると、コードエディタの上部に

という感じに表示されたら完了です!
あっさりとライブラリ追加できちゃいました。
まとめ
追加したParserの使い方については次回。
まあ、ページをみてもらえば何となく使い方がわかるとは思いますけどねw
次回はこれを使って実際にデータを取り出してみたいと思っています。
何かの参考になれば幸いです!