
少し仕事でスクレイピングっぽいことをする機会があったのですが、久々すぎてネットで検索してから思い出しつつJavaScriptを組んだ筆者だったりします。こんばんわ。
今の仕事がこういう方面から離れているところなので…という言い訳をしつつ、組んでいたところ、ぶち当たった問題がありまして。
- 同じクラス名を使っていて、欲しい情報以外のものが混ざってしまっている。
という状態でした。ちなみに、
- 欲しくない情報の方には後ろにクラス名が追加されている(例:<div class=”a-side b-side”>)
みたいな感じだったわけです。
つまり、欲しいのはa-sideだけが書かれているものなんですが、これをどうやって処理していいのやら悩んでしまった次第。
調べてみたら
しばらくこの手の情報とかに疎くなってしまっていたので…。
※再就職の活動やら資格試験の勉強やらですっかりプログラミングとかから離れてしまってましたからね(>_<)
で、なんかいい方法がないかと調べていたわけですよ。
最初は
- getElementBy~系
まあ、DOM操作での定番ですしね。
しかし、うまく操作できそうなものが見当たらない…。
そもそもタグは「div」なのでtagNameは×ですし、
クラス名で除外分だけを取り出す、それを条件文で調べていちいち除外するでは手間がかかり過ぎる。
そういえば、cssのセレクターとかならnotで除外とか使えるのになと思ったわけです。
で、そっち方面でないものかと
ん?
Document.querySelector() ?
ということで調べてみるもんですね。
どういうものなの? クエリーセレクターって?
指定された CSS セレクターにマッチする、文書内の最初の要素を示す Element オブジェクト、もしくは、もしマッチする要素がなければ null を返します。
https://developer.mozilla.org/ja/docs/Web/API/Document/querySelectorから引用
おぉ、つまりセレクターにマッチするものを取り出すことができそうな感じじゃないですか!
というわけで実験実験。
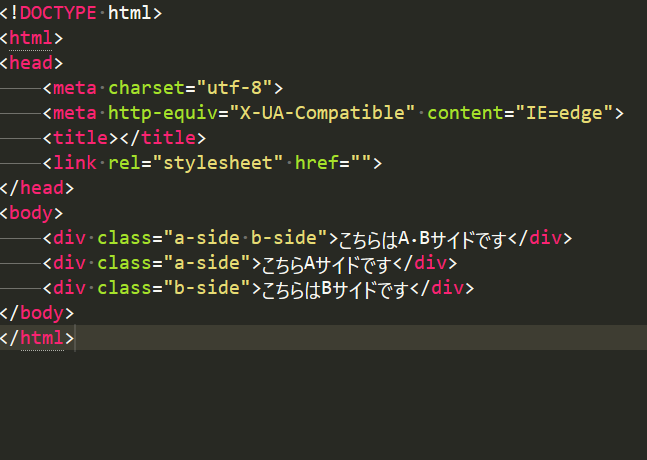
こんなものを用意してみました。
さっそく普段通りのdocument.getElementsByClassName(‘a-side’)で取り出してみたいと思います。
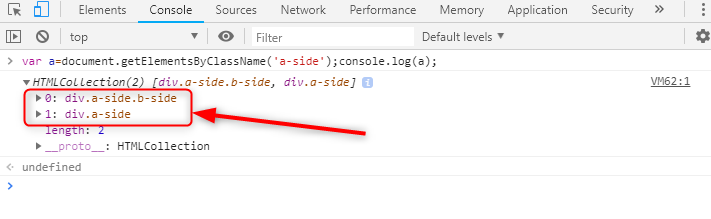
まあ、当然の結果でb-sideが混ざったものも取り出せてしまってますね。
これをquerySelectorで早速やってみましょう!
まずは普通にdocument.querySelector(‘.a-side’)としてみましょう。
※a-sideの前にドットを忘れないように!
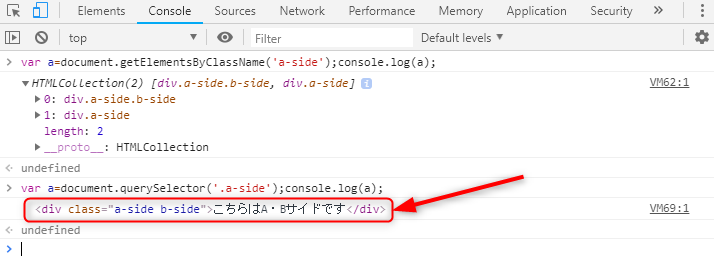
最初の混ざったものが取り出せてしまってます。
これでは困ってしまうわけですよ。これを除外して、次のa-sideだけのを取り出したい。
そこでnotセレクターを使います。
notセレクターについても軽く書いたことがあるので興味がある方は是非(*’ω’*)


ということで、次は
querySelector(‘.a-side:not(.b-side)’)
としてみます。すると、
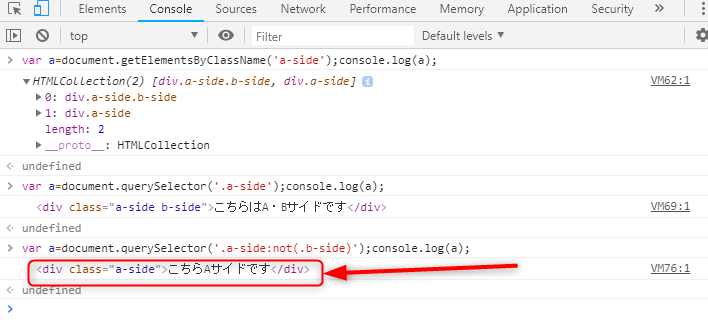
最初のb-side混ざりを除外することに成功!
バッチリですね。
まとめ
クエリーセレクターはcssのような感じで使えるので要素を取り出す際には複雑なことをしないで済むので便利ですよ!
どうやらhtml5であることが条件のようなのですが、最近のモダンブラウザならどれでも使えるはず。
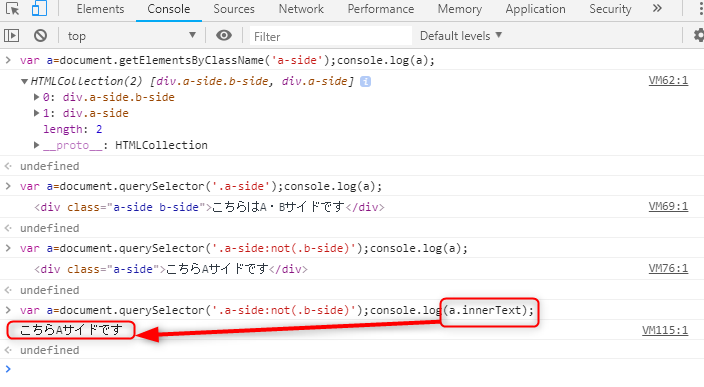
もちろん、要素のテキストを取り出したいならinnerTextでOK。
参考になれば幸いです!
…というか、自分の忘備録だな、これは(;´・ω・)