
前回に引き続き、2017年版のランキングページの作成に向けて2016年のページを参考にして抽出できるように調べていきます。
https://tks-kan.com/2017/02/13/964/
https://tks-kan.com/2017/02/15/973/
今回の目的は
- レースごとのリザルトページの中身を確認する
- 各要素を取り出すためのポイントやキーワードを探る
です。では、いってみましょう!
前回抽出した条件を再度確認
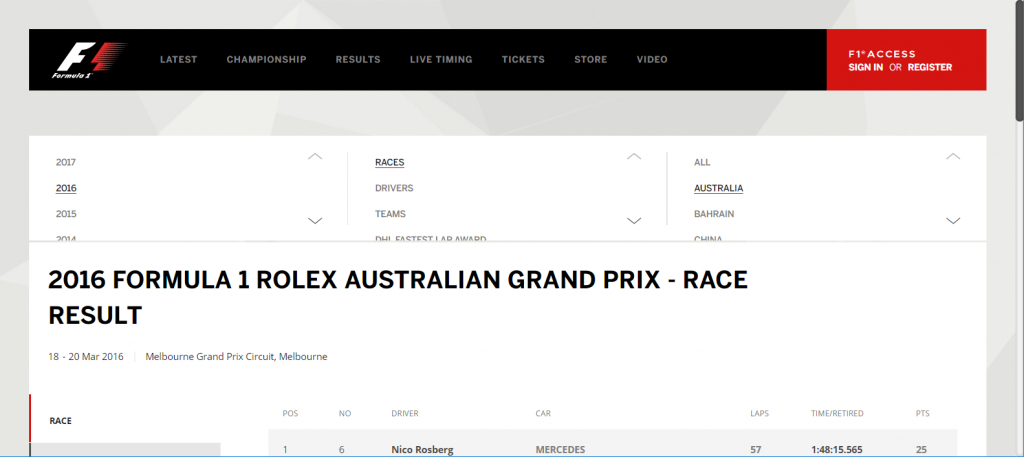
https://www.formula1.com/en/results.html/2016/races/938/australia/race-result.html
前回、2016年のリザルトページから上記のurlの抽出を行いました。その際のポイントとしては
- レースごとのurlはaタグ・クラス名「dark bold ArchiveLink」で選別できる
- 相対アドレスになっているので、頭に「https://www.formula1」を付ける必要がある
という状態でした。HSPプログラムへの落とし込む時にはもう少し細かく抽出条件を考える必要があると思いますが、とりあえずはJavaScriptで仮に調べています。
ソースコードを調べてみる
さきほどのページのソースをテキストエディタなどにコピペして、今回は全ドライバーの着順部分を探し出しだします。すると
<tr>
<td class="limiter"></td>
<td class="dark">1</td>
<td class="dark hide-for-mobile">6</td>
<td class="dark bold">
<span class="hide-for-tablet">Nico</span>
<span class="hide-for-mobile">Rosberg</span>
<span class="uppercase hide-for-desktop">ROS</span>
</td>
<td class="semi-bold uppercase hide-for-tablet">Mercedes</td>
<td class="bold hide-for-mobile">57</td>
<td class="dark bold">1:48:15.565</td>
<td class="bold">25</td>
<td class="limiter"></td>
</tr>
trタグで囲まれた中身に
- 着順
- カーナンバー
- ドライバー名
- ラップ数
- タイム(タイム差、ラップ差、リタイア)
- 獲得ポイント
が入っていますね。とりあえず、ひとつひとつのクラス名を見てみると
- 着順:dark
- カーナンバー:dark hide-for-mobile
- ドライバー名:dark bold、hide-for-tablet、hide-for-mobile、uppercase hide-for-desktop
- ラップ数:bold hide-for-mobile
- タイム(タイム差、ラップ差、リタイア):dark bold
- 獲得ポイント:bold
という感じです。どうもdarkやboldのみで検索すると分類が大変そうですね。このあたりの条件はHSPに落とし込む際に考えないといけないようです。ま、とりあえず、trを起点にJavaScriptで確認をしてみましょう。
JavaScriptで調べてみる
コンソールを利用して
- タグ「tr」
で調べてみたいと思います。
var t=document.getElementsByTagName('tr');
console.log(t);
といった感じに入力して実行してみます。結果は

22人分のデータが取り出せそうですね。さらに、1位のデータに絞って、クラス名「dark」でみてみましょう。
var t=document.getElementsByTagName('tr');
var s=t[1].getElementsByClassName('dark');
console.log(s);
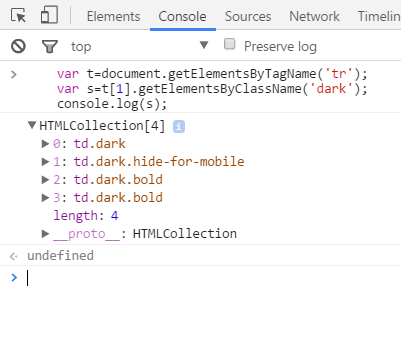
4つヒットしてますね。あらためて、さっきの分類をみてみると
- 着順:dark
- カーナンバー:dark hide-for-mobile
- ドライバー名:dark bold、hide-for-tablet、hide-for-mobile、uppercase hide-for-desktop
- タイム(タイム差、ラップ差、リタイア):dark bold
たしかに「dark」でのヒットと相違ないですね! ちなみに「t[0]」だと、ヘッダー(テーブルタグのth)の部分を取りだしてしまうので注意しましょう。
HSP用に分類条件を考えてみる
とりあえず、JavaScriptでの捜索から、取り出したい要素以外の「雑音」はなさそうなのがわかったので、次にHSP用に分類条件を考えてみます。まずtrでth部分を含めたドライバーを網羅できる状態。なので、次はthを外す必要があるのでtdのみにするか、最初にヒットしたtrを除外。
着順部分はダブルクォーテーションからふくめた「”dark”」で単独ヒットできそう。カーナンバーは「dark hide-for-mobile」で他に被りはなし。ドライバー名はダブルクォーテーション込みの「”hide-for-tablet”」「”hide-for-mobile”」「”uppercase hide-for-desktop”」。ラップ数も単独で「bold hide-for-mobile」でOK。
タイムはちょっと特殊で「dark bold」でヒットしたら、その後ろに文字が続いているかどうかで判断。改行になっている場合はドライバー名の一群、そうじゃない場合はタイムなどのデータがあると分けられそうだ。
ポイントはダブルクォーテーション込みの「”bold”」。こんな感じでしょうか。あらためて、まとめると
- trタグに囲まれた範囲である
- 着順:「”dark”」
- カーナンバー:「dark hide-for-mobile」
- ドライバー名:「”hide-for-tablet”」「”hide-for-mobile”」「”uppercase hide-for-desktop”」
- ラップ数:「bold hide-for-mobile」
- タイム:「dark bold」に加えて後ろに文字があるか否かで判定
- ポイント:「”bold”」
これを踏まえてHSPでのプログラミングに取り掛かりたいと思います。
まとめ
今回はここまで。引き続き下調べでした。これでこのページから要素を取り出すための条件が大体判明しました。次回はいよいよHSPにてページダウンロードから要素の取り出し確認などをしていきたいと思います。お楽しみに!