以前、[F1公式サイトのスクレイピング](アドレス)でも取り扱ったんですが、今回はもっと手軽に情報を取得できるようにHSPを使って、最終的にはローカルで見られるランキングページを作成してみたいと思います。以前のスクレイピングのページは以下からどうぞ。
https://tks-kan.com/2016/08/10/74/




まずは準備準備
まずはアクセスするページのURLを調べましょう。F1の2016年シーズンのポイントランキングのページのURLは
https://www.formula1.com/en/results.html/2016/drivers.html
で、以前、スクレイピングで調べた際の情報も記載しておきましょう。HSPでもJavascriptと同様にクラス名とかを判断基準にデータを取り出すことになるはずなので。。。
- 【ドライバー名】
- ファーストネーム→クラス名(hide-for-tablet)、タグ(span)
- ファミリーネーム→クラス名(hide-for-mobile)、タグ(span)
- 【国籍】
- クラス名(dark semi-bold uppercase)、タグ(td)
- 【所属チーム】
- クラス名(grey semi-bold uppercase ArchiveLink)、タグ(a)
- 【獲得ポイント】
- クラス名(dark bold)、タグ(td)
という感じでしたね。HSPについては


の「今回の主役たちを紹介」の部分に簡単にまとめてありますのでご参照くださいませ。
ポイントランキングのページをダウンロードするプログラムを作る
まずは解析する対象のページをダウンロードするプログラムを書いていきましょう。最初にネットに接続できているかのチェックから。
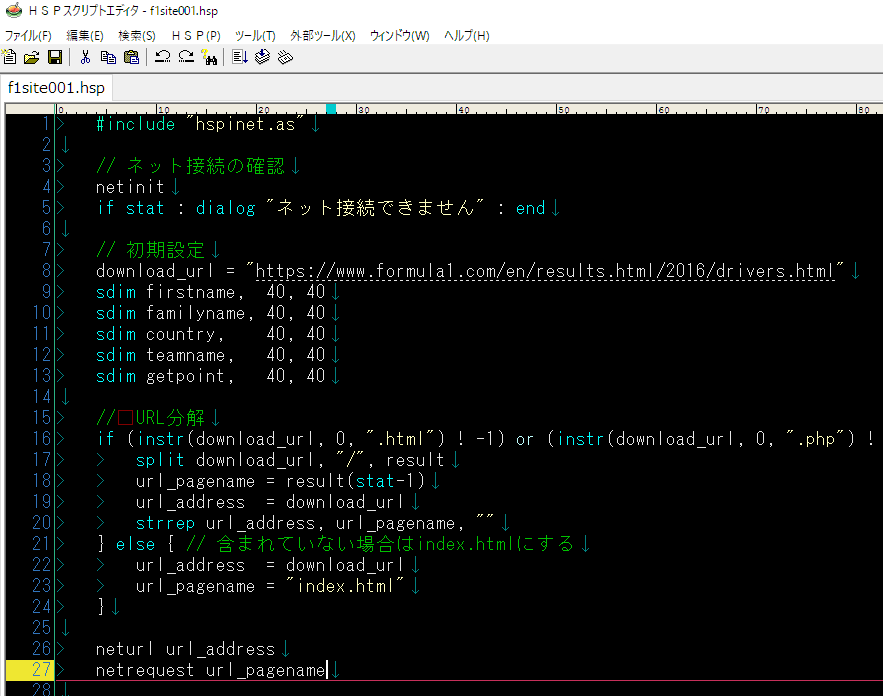
#include "hspinet.as" // ネット接続の確認 netinit if stat : dialog "ネット接続できません" : end
次に各種設定を記述していきましょう。あとから追加していくことになるかもですが、ひとまず思いつくのは
- ダウンロードしたいページのURL
- ドライバー名の入れ物(ファーストネームとファミリーネームを別々に)
- 国籍の入れ物
- 所属チームの入れ物
- 獲得ポイントの入れ物
という感じでしょうか。それぞれ適当に
// 初期設定 download_url = "https://www.formula1.com/en/results.html/2016/drivers.html" sdim firstname, 40, 40 sdim familyname, 40, 40 sdim country, 40, 40 sdim teamname, 40, 40 sdim getpoint, 40, 40
urlをHSPの形式に合うように処理しておきます。HPSでは上のdownload_url設定でいうところのdrivers.htmlとそれ以前の部分とに分けてあげる必要があります。もちろんそのまま初期設定に記述してもいいのですが、少しプログラムっぽいことをして分解してみましょう。ここではsplitという命令を使います。以下、HSPのリファレンスから引用
split
文字列から分割された要素を代入split p1,”string”,p2…
p1=変数 : 元の文字列が代入された変数
“string” : 区切り用文字列
p2=変数 : 分割された要素が代入される変数
というわけで、スプリットって単語からもなんとなく想像がつく命令じゃないでしょうか。urlで//で分解してあげれば目的は果たせそうです。だたし、urlに.htmlや.phpなどが含まれていない場合も考慮しておく必要があると思うのでその点は注意しましょう。そのチェックはinstrを利用します。
instr()
文字列の検索をするval = instr(p1,p2,”string”)
p1=変数名 : 検索される文字列が格納されている文字列型変数名
p2=0~(0) : 検索を始めるインデックス
“string” : 検索する文字列
これをif文にかましてあげて、.htmlや.phpが含まれている場合は分解、そうでないなら分解しないという判断で進めましょう(指定した文字列が含まれていない場合には「-1」の値が返ってくるのでそれを利用)。また、分解した際の入れ物はurl_addressとurl_pagenameにしておきます。
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
そうしたら、次はダウンロード~ダウンロード実行中のエラー判定、エラー時の処理、ダウンロード成功時のメッセージ表示を書いていきます。先ほど分解したurl_addressとurl_pagenameをそれぞれneturlとnetrequestの命令で使用してます。イメージとしては、neturlでその階層まですすめて、netrquestでそのページにアクセスするという感じでしょうか。あくまでイメージなので詳細はリファレンスで確認してくださいね。
neturl url_address netrequest url_pagename *main //取得待ち確認 netexec res if res > 0 : goto *comp if res < 0 : goto *bad await 50 goto *main *bad //エラー neterror estr mes "ERROR "+estr stop *comp mes "DOWNLOAD 完了" stop
これを実行すると

と表示されれば無事ダウンロード完了です。スクリプトファイル(プログラム)と同じフォルダ内にdriver.htmlがあると思います。それをブラウザで開くと
無事にダウンロードできているようですね。では次回はこのファイルを使ってHSPを使っての解析(スクレイピング)をしていきましょう。
まとめ
今回のコードを載せておきますね。試してみてください~!
#include "hspinet.as"
// ネット接続の確認
netinit
if stat : dialog "ネット接続できません" : end
// 初期設定
download_url = "https://www.formula1.com/en/results.html/2016/drivers.html"
sdim firstname, 40, 40
sdim familyname, 40, 40
sdim country, 40, 40
sdim teamname, 40, 40
sdim getpoint, 40, 40
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
neturl url_address
netrequest url_pagename
*main
//取得待ち確認
netexec res
if res > 0 : goto *comp
if res < 0 : goto *bad
await 50
goto *main
*bad
//エラー
neterror estr
mes "ERROR "+estr
stop
*comp
mes "DOWNLOAD 完了"
stop