前回はレースリザルトのURLの抽出とCSV形式で保存までできました。今回は保存したCSVと取り出したURLを比較して、CSVには存在していないものがあった場合に追加するという処理を考えていきたいと思います。【その6】であげた目標
- プログラムを実行すると自動的にレース結果のURLを取得する
- URLの取得は今まで取得していなかったもののみ
- 取得したURLデータをなんらかの形式でデータ保存しておく(参照する為に)
- 2016年版で実行してみて、2017年版にフィードバックする
の2番目と3番目の一部に該当しますね。それでは進めてまいりましょー。
URLで比較させる
CSVにはレース名とURLが保存されている形になっています。となると必然的に
- レース名
- URL
どちらかで比較をすることになると思います。…ま、いっそのこと両方チェックしてしまう手もありかもしれませんが、ここではURLでの比較としました。
フローを考えてみる
どういった手順で比較をするか、存在しなければ追加するか、フローを考えてみましょう。
1. ページをダウンロードする
2. CSVファイルが存在するか確認する(なければ新規作成)
3. CSVファイルを読み込んでおく(新規作成の場合はCSV作成用のテキスト用意)
4. ダウンロードしたページからURLを抽出
5. 抽出したURLとCSVの中身を比較
6. URLと同じものが存在している場合は次のURL抽出へ
7. 無かった場合はCSVに追加するためにテキスト成形する
8. 読み込んだCSVに追加して保存する(すべて既存の場合はそのまま何もせず終了)
ポイントになってくるのは2、3、5あたりですね。では、これに沿ってプログラムを考えていきましょう。
ページをダウンロード~CSVファイルを読み込んでおく(1~3)
ページのダウンロードはいままでので大丈夫。
/* 第一回で作成したダウンロード部分 */
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
neturl url_address
netrequest url_pagename
*main
//取得待ち確認
netexec res
if res > 0 : goto *comp
if res < 0 : goto *bad
await 50
goto *main
*bad
//エラー
neterror estr
mes "ERROR "+estr
stop
*comp
mes "DOWNLOAD 完了"
CSVの存在を確認するという部分には「dirlist」命令を使います。
dirlist p1,”filemask”,p2
p1=変数 : ディレクトリ一覧を格納する文字列型変数
“filemask” : 一覧のためのファイルマスク
p2=0~(0) : ディレクトリ取得モード
filemask部分にcsvのファイル名を書くことによって、dirlist命令を実行するとファイルが存在していないならstatに0が入る。これを利用します。そしてファイルの有無によって新規作成と読み込みの処理をしてあげます。
dirlist chk, "Raceresulturl.csv"
await 1
if (stat = 0) {
(CSVファイルの新規作成)
} else {
(CSVファイルの読み込み)
}
こんな感じ。新規作成側には
csv_text = "GP Name,URL\n"
ファイル読み込み側は
notesel csv_text noteload "Raceresulturl.csv" noteunsel
csv_textを用意して、内容を読み込むという処理をしておきます。note系の命令はテキストを扱う上で使い勝手がいいので、覚えて損はないですよ。
ページからURL抽出~無かった場合はCSVに追加するためにテキスト成形する(4~7)
抽出部分はそのままでいいのですが、ここにCSVとの比較を組み込む必要があります。
/*url抽出部分*/
lfcc url_pagename
notesel htmlfile
noteload url_pagename
url_cnt = 0
repeat notemax
noteget text_line, cnt
// RACE_URL
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
split text_line, "\"", buf
(この辺りにcsvとの比較を入れる)
geturl(url_cnt) = buf(1)
noteget gpname(url_cnt), cnt+1
strrep gpname(url_cnt), " ", ""
gpname(url_cnt) += " GP result"
url_cnt++
}
loop
//test
//dialog geturl(0)
//dialog gpname(0)
noteunsel
さて、csvとの比較。中身はcsv_textに入っていますし、この中身に抽出したURLと同じ文字列があれば、すでに抽出済みと考えても良さそうですよね。というわけで
if (instr(csv_text, 0, buf(1)) ! -1) : continue
「continue」はその場でloop処理をするのと同じ効果があります。なので、「csv_textの中に抽出したURLがある場合はloop処理しなさい」という動きになります。
読み込んだCSVに追加して保存する(8)
前回までのcsv作成部分のコードは
//make_csv
csv_text = "GP Name,URL\n"
repeat 40
if gpname(cnt) = "" : break
csv_text += gpname(cnt) + ",https://www.formula1.com" + geturl(cnt) + "\n"
loop
こんな状態。これだと
csv_text = "GP Name,URL\n"
この部分でcsv_textをリセットしてしまうことになるので、これをコメントアウトしておきます。あとは問題なさそうですね。
そして最後、csvに変更がないなら保存しないで終了という部分です。この判定は逆に考えてみましょう。もし更新がある場合には保存する。更新があるかどうかはgpname(0)にテキストが入っているかどうかでわかります。なので、
if (gpname(0) ! "") {
notesel csv_text
notesave "Raceresulturl.csv"
noteunsel
await 1
dialog "save new csv file"
}
gpname(0)の中身がカラではない場合は、保存処理をして「save new csv file」とダイアログを出すという処理にしました。
これでプログラミングは完了。実験してみましょう。
真っ新なフォルダにて実行してみる

ここで実行することで、ダウンロードしたhtmlファイルとcsvファイルが作られるはずです。
ダウンロード完了とセーブしたダイヤログの表示が出て…
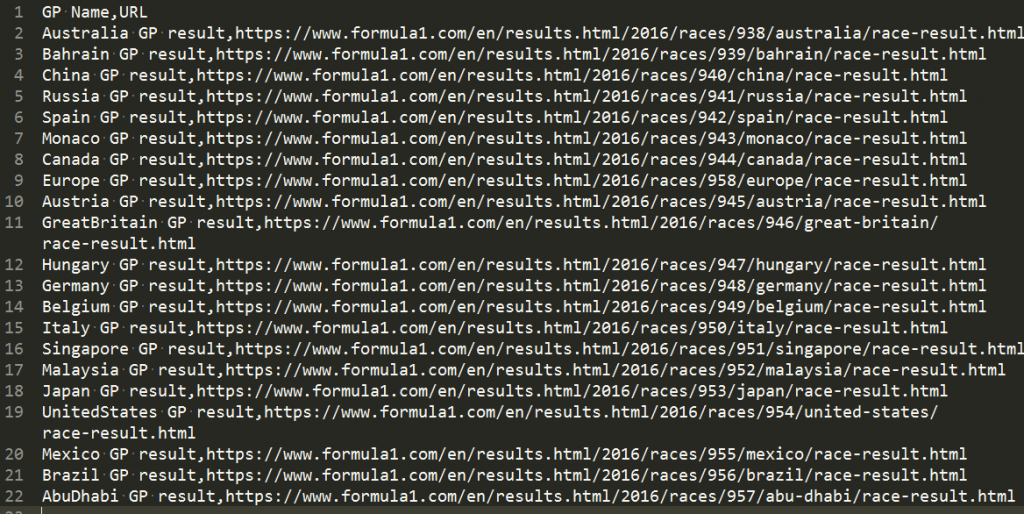
ちゃんとファイルが作られました。
csvファイルの中身をいじってみる
実際には終わったレースの結果が掲載されることで増えていく仕組みなので、csvの後ろ数戦分を削ってみて、実行してみましょう。
日本GPまで削ってみます。で、実行してみると…
ちゃんと後ろに追加されていますね!
まとめ
今回はここまで。今回はURLの比較と新しく発見したものは追加という流れを作りました。次回は保存したcsvからurlを取り出して、それぞれのGPのhtmlをダウンロードするプログラムに挑戦していきたいと思います。では、例によって今回のコードです! コピペで試してみてください。
//HSPモジュール SAKMISさんのを使用しています
//命令→lfcc ファイルネーム
//読み込み→改行置換→保存
#module
#deffunc lfcc str filename
; mref filename,32
; mref status,64
exist filename
size=strsize
if size=-1 : status=-1 : return
sdim ss,size+1,1
bload filename,ss,size
ii=0
code=0
sdim data,size<<1,1
repeat size
tt = peek (ss,cnt)
if tt=10 : code=10 : break
if tt=13 {
code=13
tt = peek (ss,cnt+1)
if tt=10 : code=0
break
}
loop
if code=0 : status=-1 : return
repeat size
tt = peek (ss,cnt)
if tt=code : wpoke data,ii,2573 : ii+2 : continue
poke data,ii,tt : ii++
loop
bsave filename,data,ii
status=ii
return
#global
#include "hspinet.as"
// csv_check
dirlist chk, "Raceresulturl.csv"
await 1
if (stat = 0) {
csv_text = "GP Name,URL\n"
} else {
notesel csv_text
noteload "Raceresulturl.csv"
noteunsel
}
// ネット接続の確認
netinit
if stat : dialog "ネット接続できません" : end
// 初期設定
// download_url = "https://www.formula1.com/en/results.html/2017/drivers.html"
// download_url = "https://www.formula1.com/en/results.html/2016/races/938/australia/race-result.html"
download_url = "https://www.formula1.com/en/results.html/2016/races.html"
sdim firstname, 40, 40
sdim familyname, 40, 40
sdim country, 40, 40
sdim teamname, 40, 40
sdim getpoint, 40, 40
// 追加したもの
sdim position, 40, 40
sdim carnumber, 40, 40
sdim laps, 40, 40
sdim times, 40, 40
sdim geturl, 200, 40
sdim gpname, 200, 40
/* 第一回で作成したダウンロード部分 */
// URL分解
if (instr(download_url, 0, ".html") ! -1) or (instr(download_url, 0, ".php") ! -1) { //.html .phpが含まれているなら
split download_url, "/", result
url_pagename = result(stat-1)
url_address = download_url
strrep url_address, url_pagename, ""
} else { // 含まれていない場合はindex.htmlにする
url_address = download_url
url_pagename = "index.html"
}
// チェック用分岐
//goto *skippoint
neturl url_address
netrequest url_pagename
*main
//取得待ち確認
netexec res
if res > 0 : goto *comp
if res < 0 : goto *bad
await 50
goto *main
*bad
//エラー
neterror estr
mes "ERROR "+estr
stop
*comp
mes "DOWNLOAD 完了"
//stop
/*url抽出部分*/
*skippoint //チェック用ラベル
lfcc url_pagename
notesel htmlfile
noteload url_pagename
url_cnt = 0
repeat notemax
noteget text_line, cnt
// RACE_URL
if (instr(text_line, 0, "dark bold ArchiveLink") ! -1) {
split text_line, "\"", buf
// csv_text check
if (instr(csv_text, 0, buf(1)) ! -1) : continue
// geturl
geturl(url_cnt) = buf(1)
noteget gpname(url_cnt), cnt+1
strrep gpname(url_cnt), " ", ""
gpname(url_cnt) += " GP result"
url_cnt++
}
loop
//test
//dialog geturl(0)
//dialog gpname(0)
noteunsel
//make_csv
//csv_text = "GP Name,URL\n"
repeat 40
if gpname(cnt) = "" : break
csv_text += gpname(cnt) + ",https://www.formula1.com" + geturl(cnt) + "\n"
loop
// csv出力
if (gpname(0) ! "") {
notesel csv_text
notesave "Raceresulturl.csv"
noteunsel
await 1
dialog "save csv file"
}
end
stop