
ここからは今まで出力したものを利用してランキングなどを表示する仕組みを作っていきたいと思います。今回は全レース結果のCSVからドライバーポイントランキングを計算して出力するようにしてみたいと思います。
CSVにどのようにデータを格納していたか確認してみる
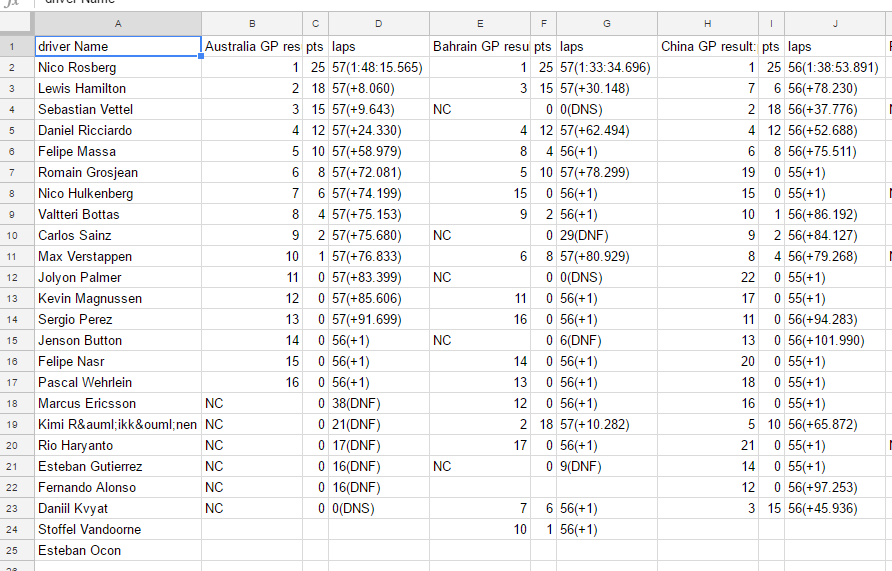
項目をみてみると一番最初にドライバー名が入っており、後はGP名(順位)、ポイント、ラップ(タイム差)の繰り返しとなってます。今回使用するのはドライバー名とポイント部分なので、取り出したいデータの場所は
- ドライバー名:1番目
- ポイント:(3 × n – 1)番目 n=第n戦目のGP
となります。ただ、hspではデータの数を数える際、一番最初が「0」になるので実際の場所は
- ドライバー名:0番目
- ポイント:(3 × (n + 1) – 1 )= (3 × n + 2)番目 n=第n戦目のGPで0からスタートする
少し混乱するかもですが n=0、1、2、3 となっていくとポイントが格納されている場所が 2、5、8、11 と変化していくことになります。ちなみにレース数の割り出し方法は
notesel allresult_csv noteget text_line, 0 split text_line, ",", buf race_cnt = (stat - 1) / 3
split命令で分割できた数がstatに格納されるのを利用します。一番最初がドライバー名なので1を引いて3個ワンセットで1グランプリなので3で割って答えを出しています。splitの区切り文字はCSVファイルなので「,」になります。
ドライバー名を取り出す
まずはドライバー名を取り出します。これはそれぞれ一番最初(0番目)にあるデータなので
notesel allresult_csv
(中略)
repeat notemax, 1
noteget text_line, cnt
split text_line, ",", csv_data
driver_name(cnt) = csv_data(0)
loop
これでドライバー名が取り出せました。
割り出したレース数を使ってrepeat処理
次にレース数を割り出したのでそれを使って繰り返し(repeat)処理していきます。これはドライバー名を取り出す繰り返し処理の中に入れ子の形で挿入します。
(略)
driver_name(cnt) = csv_data(0)
repeat race_cnt
loop
loop
レース数に応じて取り出したいのはポイント部分なので
csv_data(3*cnt+2)
この形で取り出せます。ただし、csvのデータを「テキスト」として扱っているので、これを数字にしてあげる必要があります。ランキングにするためにはポイントの合計を数字の計算で出したいですからね。なので
int(csv_data(3*cnt+2))
となります。これを合計するので
sum_point += int(csv_data(3*cnt+2))
そして、ドライバー事にポイントをリセットしておく必要があり、合計したものはドライバー毎に格納してあげたいので以下のようにしました。
(略)
driver_name(cnt) = csv_data(0)
sum_point = 0
repeat race_cnt
sum_point += int(csv_data(3*cnt+2))
loop
driver_point(cnt) = sum_point
loop
ここまでちゃんと出来ているかを確認してみます。driver_pointの後ろに
mes driver_name(cnt) + "\t:" + driver_point(cnt)
を追加して実行してみると
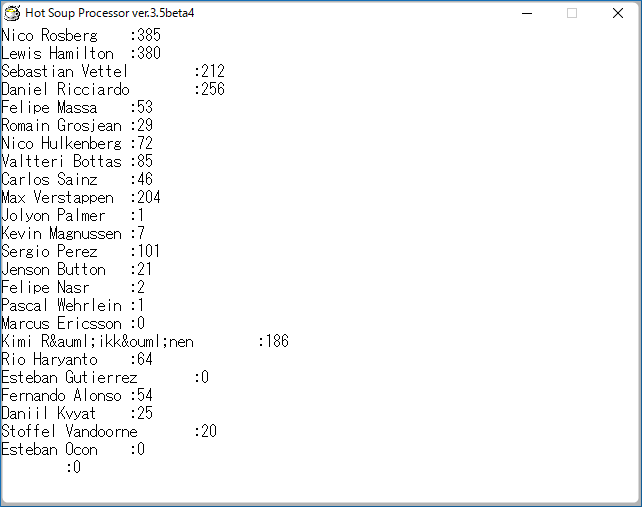
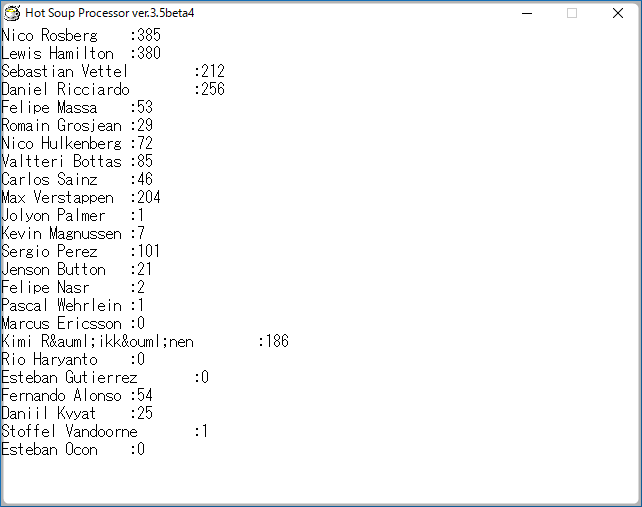
なんとなくあっているような感じですが、実際に昨年取得して出力していたhtmlと見比べてみると
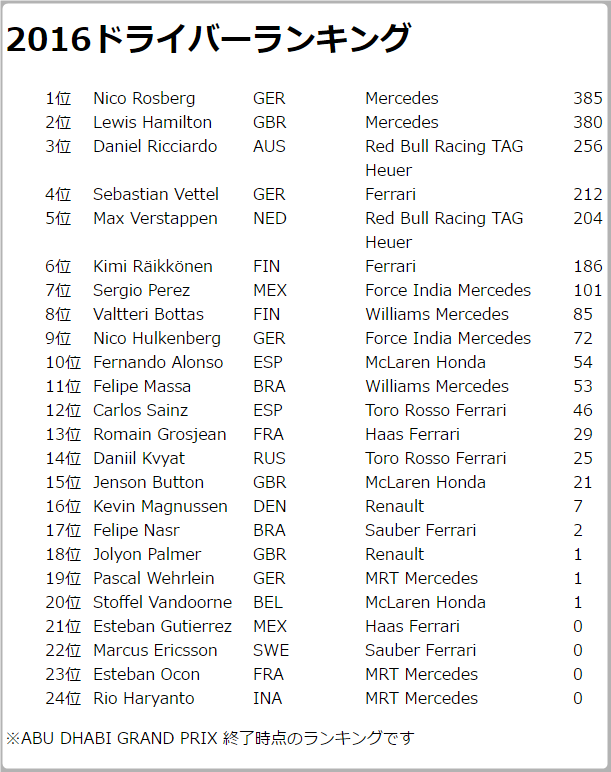
HaryantoとVandoorneの部分がオカシイですね。Vandoorneで考察してみましょう。たしかピンチヒッターで一度参戦した以降はデータがない状態なので、レース数分の計算処理をする段階で何か関係ないデータを加算しているんじゃないかなと推測できます。Haryantoもどうようにデータが足りないドライバー。つまり、データが足りないドライバについては、そのフォローをする処理を考えておく必要がありそうです。
データが足りない場合の回避処理
今まではレース数を最初の項目数で割り出して全てのドライバーに適用していましたが、データが少ないドライバーも出現する可能性があることが判明したので、ドライバー毎にレース数を割り出す方法に変更しました。基本的な計算は変わらないので
split text_line, ",", buf race_cnt = (stat - 1) / 3
この部分を消去し
repeat notemax, 1
noteget text_line, cnt
split text_line, ",", csv_data
driver_name(cnt) = csv_data(0)
この後ろに
race_cnt = (stat - 1) / 3
を追加してあげます。これによってドライバー毎にレース数が変わるようになるので、データが足りない場合でも計算違いは出てこないはずです。実行してみると
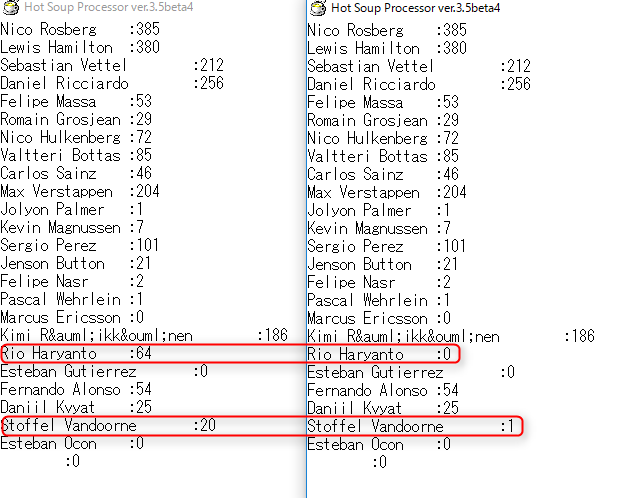
大丈夫そうですね! あと気になるのはドライバー名がない一番下の表示。これはドライバー名がなければ処理を回避するようにすればいいので
if csv_data(0) = "" : break
を繰り返し処理に追加してあげればOK
まとめ
今回はここまでとします。次回はポイント順にソートして、簡易的ではありますがhtml出力を予定しています。そしてできれば各レース結果とリンクを張ることにもチャレンジしてみたいと思います。今回も全コードを載せておきます~(今まで作成したファイルがないと動かないのでお気を付けくださいませ)。
// into_pos
home_pos = dir_cur
html_pos = dir_cur + "\\html"
csv_pos = dir_cur + "\\csv"
// folder_check
dirlist chk, "*.*", 5
if instr(chk, 0, "html") = -1 : mkdir "html"
if instr(chk, 0, "csv") = -1 : mkdir "csv"
// csv_check
chdir home_pos
dirlist chk, "Raceresulturl.csv"
await 1
if (stat = 0) {
csv_text = "GP Name,URL\n"
} else {
notesel csv_text
noteload "Raceresulturl.csv"
noteunsel
}
chdir csv_pos
dirlist chk, "allresult.csv"
await 1
if (stat = 0) {
allresult_csv = "driver Name"
} else {
notesel allresult_csv
noteload "allresult.csv"
noteunsel
}
// 初期設定
sdim driver_name, 40, 40
dim driver_point, 40, 40
//main
notesel allresult_csv
repeat notemax, 1
noteget text_line, cnt
split text_line, ",", csv_data
if csv_data(0) = "" : break
driver_name(cnt) = csv_data(0)
race_cnt = (stat - 1) / 3
sum_point = 0
repeat race_cnt
sum_point += int(csv_data(3*cnt+2))
loop
driver_point(cnt) = sum_point
mes driver_name(cnt) + "\t:" + driver_point(cnt)
loop
stop